2023.10.10 コラム
データ分析入門!CRISP-DMを手順に落とし込んでみる -ビジネス理解~データ準備編-
● はじめに
CDPなどで顧客に関連するデータを集約している企業様が増えている一方で、
実態としては「データ活用での結果が見えづらい」「施策まで活用できていない」といったお話を聞くことが多いです。
データ分析を始めようとしても、何から手を付けていいのかわからないという方や、データ分析を始めたはいいものの、分析結果がうまく出ない・施策まで活用できていないといった方に、CRISP-DMの考えを元にしたデータ分析の流れを解説します。
● CRISP-DMとは
Cross-Industry Standard Process for Data Mining(CRISP-DM)は、10年以上前から存在し、最も広く使用されている分析プロセス標準です。
CRISP-DMは、欧州連合の資金援助を受けて、200以上の関係機関が参加するコンソーシアムが開発した、誰でも利用できるオープンな標準規格です。
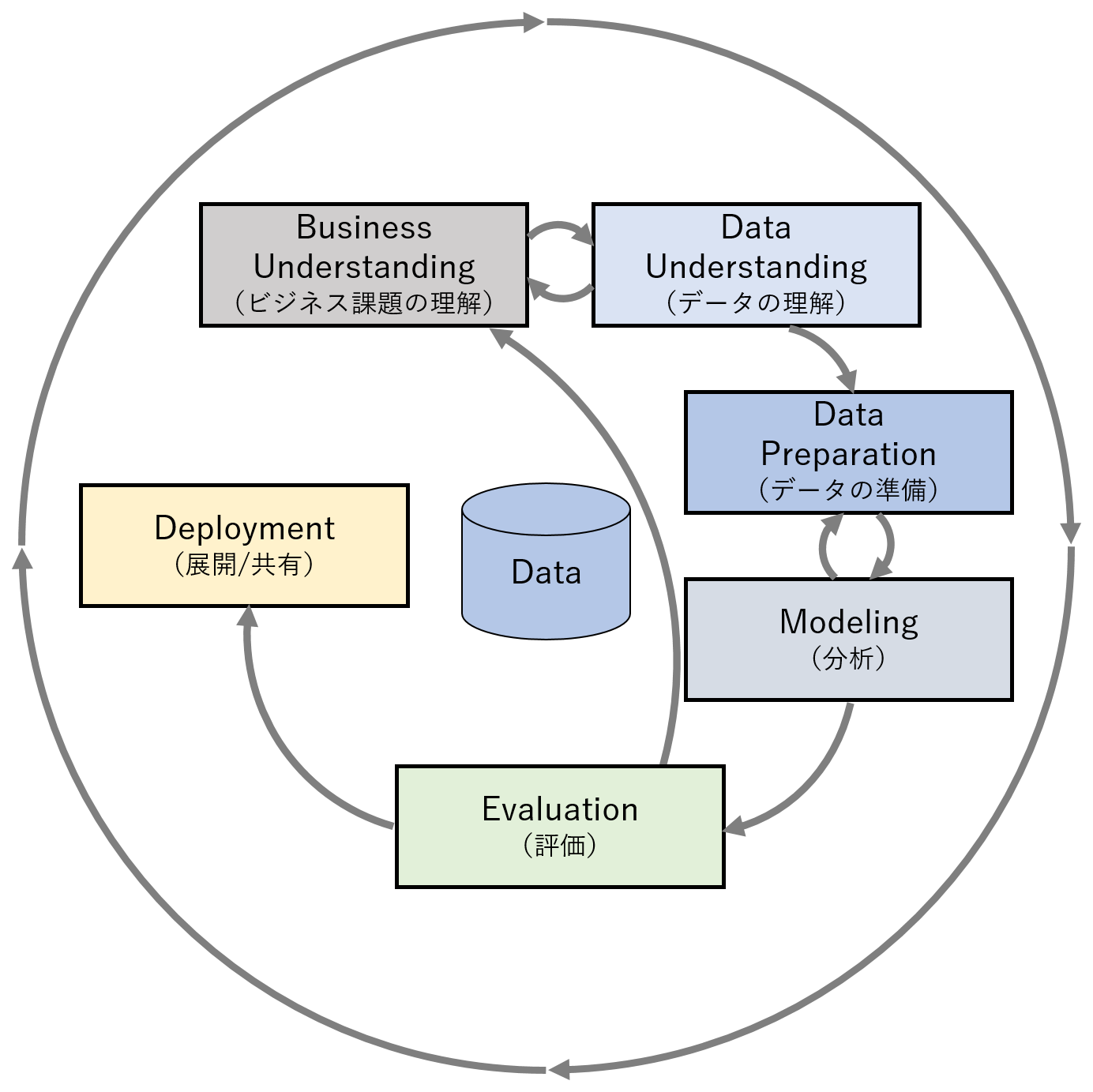
図のように、分析は以下のプロセスで構成されます。
- ビジネスの理解
- データ理解
- データの準備
- モデリング(分析)
- 評価
- デプロイメント(展開)
「データ分析」というと、いわゆる統計分析や機械学習のモデリングのようなものを想像されることが多いかと思いますが、それはあくまでデータ分析を構成する1プロセスにすぎず、実はその前後のプロセスが重要になります。
前のプロセスがしっかりできていないと、4.モデリング(分析)を行ってもうまく示唆が得られない、結果が得られない等といったケースになることが多いと感じます。
かといって、このプロセスを見ただけで完璧なデータ分析を行うことは中々難しいので、
これらのプロセスを手順(実際にやること)に落とし込んでみました。
今回は、1. ビジネスの理解 と 2. データの理解について解説いたします。
一例として参考にしていただければと思います。
● ビジネスの理解
1つ目のプロセス「ビジネスの理解」では、データ以前に、そもそもビジネスの目的は何か?を明確にすることが重要です。
目的を明確にする前にデータを見てしまうと、データありきの仮説を立ててしまったり、分析の目的を見失ってしまったりといった誤りを起こしがちです。
そのため、いきなりデータを見るのではなく、まずはビジネスの理解から始めます。
- ビジネスの理解
- ビジネス課題の整理・分解
- 論点に対する重要度(インパクト)の割り当て
- 論点に必要なデータの割り当て
ビジネス課題の整理において、ロジックツリーを作成することは一つの手段になります。
例えば、KPIを頂点にしたロジックツリーを作成し、頂点のKPIを構成する指標を洗い出していくことで、目標に対する要素が整理できます。
また、最も重要な課題を頂点としたり、最も重要なアクションを頂点とする等、ケースに合わせて様々な形でのロジックツリーが考えられます。
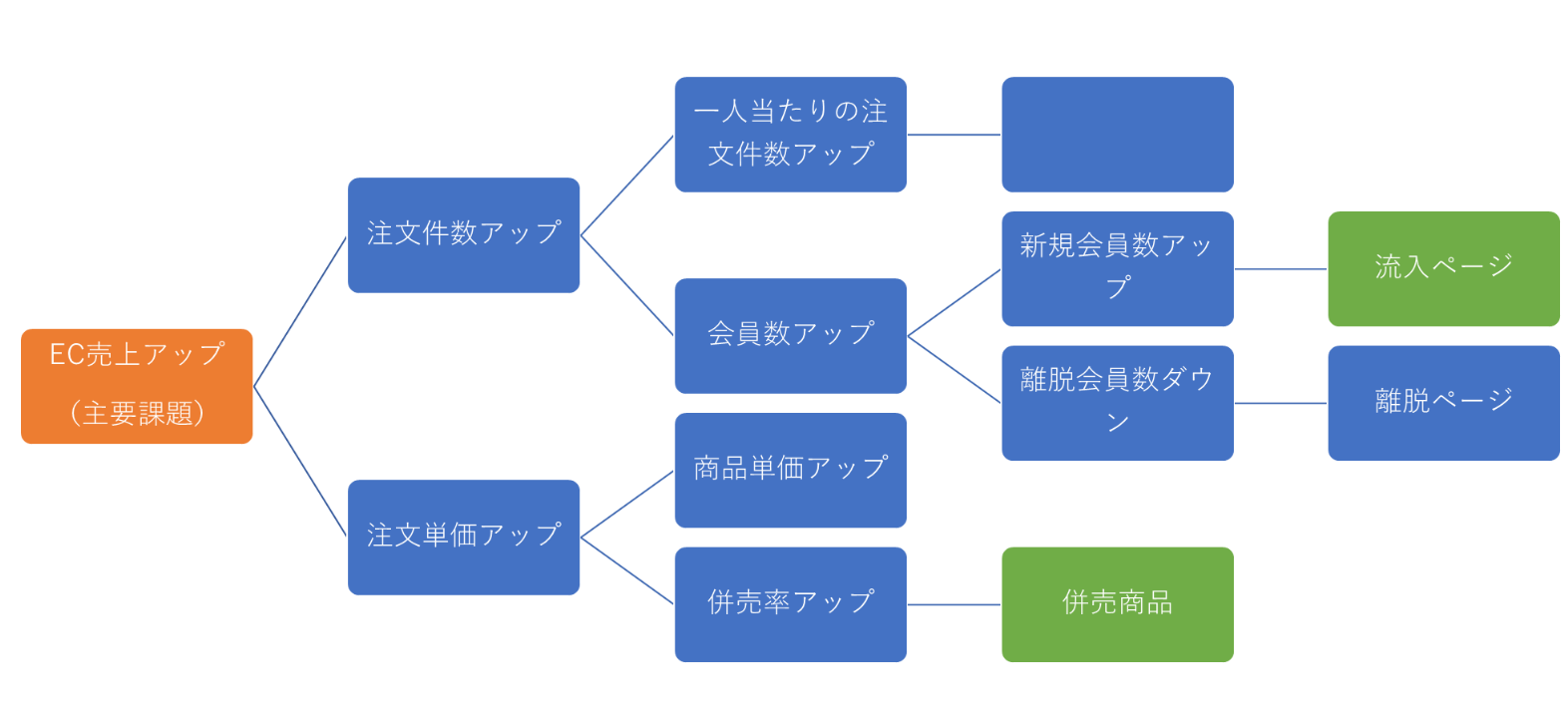
KPIツリーを作成して論点を整理したら、各論点に対して、重要度(その論点を改善すればどのくらいインパクトがあるか)と、その論点の検証に必要なデータも当てはめていきます。
この時、データの有無や取得可否にとらわれず、あくまでその論点(指標)に必要かどうかで考えることがポイントです。
● データ理解~データの準備
2つ目のプロセス「データ理解」では、ビジネス理解で定めた後続のプロセスに向けてデータの理解を深めます。特に、データの全体像をつかむことが重要です。
データ理解の方法として、代表的なものにExplanatory Data Analysis(EDA:探索的データ分析)というものがあります。EDAは、厳密にはデータ理解のプロセスのみにとどまるものではありませんが、今回はデータ理解におけるEDAについてご紹介します。
EDAは、その名の通り、データに触れて(探索しながら)特徴を理解することを目的とします。クライアント環境にあるデータや外部データなど、対象データについて理解が深くない状態から分析を行う場合に役立ちます。
データ分析初心者がデータを理解するにあたり、まず行うべき最低限のデータ探索は以下のようなものがあります。
- どのテーブルにどんなデータが入っているのか理解する
- データに欠損がないか確認する(日付、IDの突合率、n数、要約統計量、分布)
- 必要な前処理を把握する
まず、テーブル単位でどんなデータが入っているのかを把握します。あくまでどんなデータがあるのかを把握するためなので、IF定義などの詳細までは、ここでは必須ではありません。また、同様の複数テーブルがある場合はデータセット単位など、ケースバイケースで最適な粒度でデータを把握します。
また、データ分析を行う前に、データ全体の特徴をつかむ必要があります。日付に欠損はないか・複数テーブルを紐づけている識別子(ID)はどのくらい紐づくか(突合率)・n数・データの分布など。
いわゆる要約統計量とよばれる指標は、データの全体像をつかむのに役立ちます。箱ひげ図や散布図を作成すると一目でわかるのでおススメです。
上記のようなデータ探索の結果をまとめることで、おのずとデータ分析のために必要な前処理がわかります。これがデータの準備にあたります。
● まとめ
今回、CRISP-DMの考え方を基に、データ分析の流れについて解説いたしました。もし機会があれば、モデリング(分析)以降のプロセスについても詳細を解説したいと思いますが、あくまで一例として参考にしていただければ幸いです。
弊社では、分析サービスもご提供しておりますので、お気軽にご相談ください。
▼分析支援サービス資料はこちら
⇒【ダウンロード資料】データ活用サポート | 分析支援サービス
⇒【ダウンロード資料】期間限定|顧客分析パッケージ
▼データ分析についてのコラムはこちら
⇒GTM × GA4 × BigQuery|サーバーサイドCookie単位でUB集計してみた
⇒GTM×GA4×BigQuery|バスケット分析による鉄板コンテンツ
⇒GTM × GA4 × BigQuery|データ統合の基本!マッピングテーブル構築
⇒GTM × GA4 × BigQuery|サーバーサイドCookieを活用したn1解析
本件に関するお問い合わせは下記にて承ります。
株式会社DataCurrent
info@datacurrent.co.jp