2025.02.12 コラム
BigQueryにおけるクエリの最適化
DataCurrentの大塚です。
BigQueryを使って変換処理を流していた際のことです。 下記のようなエラーで処理が止まってしまいました。
Query exceeded resource limits. This query used *** CPU seconds but would charge only ***M Analysis bytes. This exceeds the ratio supported by the on-demand pricing model. Please consider moving this workload to a capacity-based pricing model, which does not have this limit. *** CPU seconds were used, and this query must use less than *** CPU seconds.
割り当てと上限のページによると、BigQueryをオンデマンドモデルで契約している場合はスキャンされるデータ量あたりで使用可能なCPU使用量に上限が設定されています。
変換処理のクエリがこのリソース上限に引っかかってしまったことが今回のメッセージの原因でした。 この問題を以下の観点で修正したため、その際に調べたり検証したことについてお話しします。
- WITH句を一時テーブルにする
- JOINの条件をシンプルにする
- JOINのOR条件をUNION ALLで代用する
WITH句を一時テーブルにする
WITH句でまとめた処理を複数箇所で参照するようなことがあると思います。 この処理結果の実行グラフを見てみると、WITH句を使って書いている処理が複数箇所に出現し、同じ処理を何度も実行していることが分かります。(下図のイメージ)
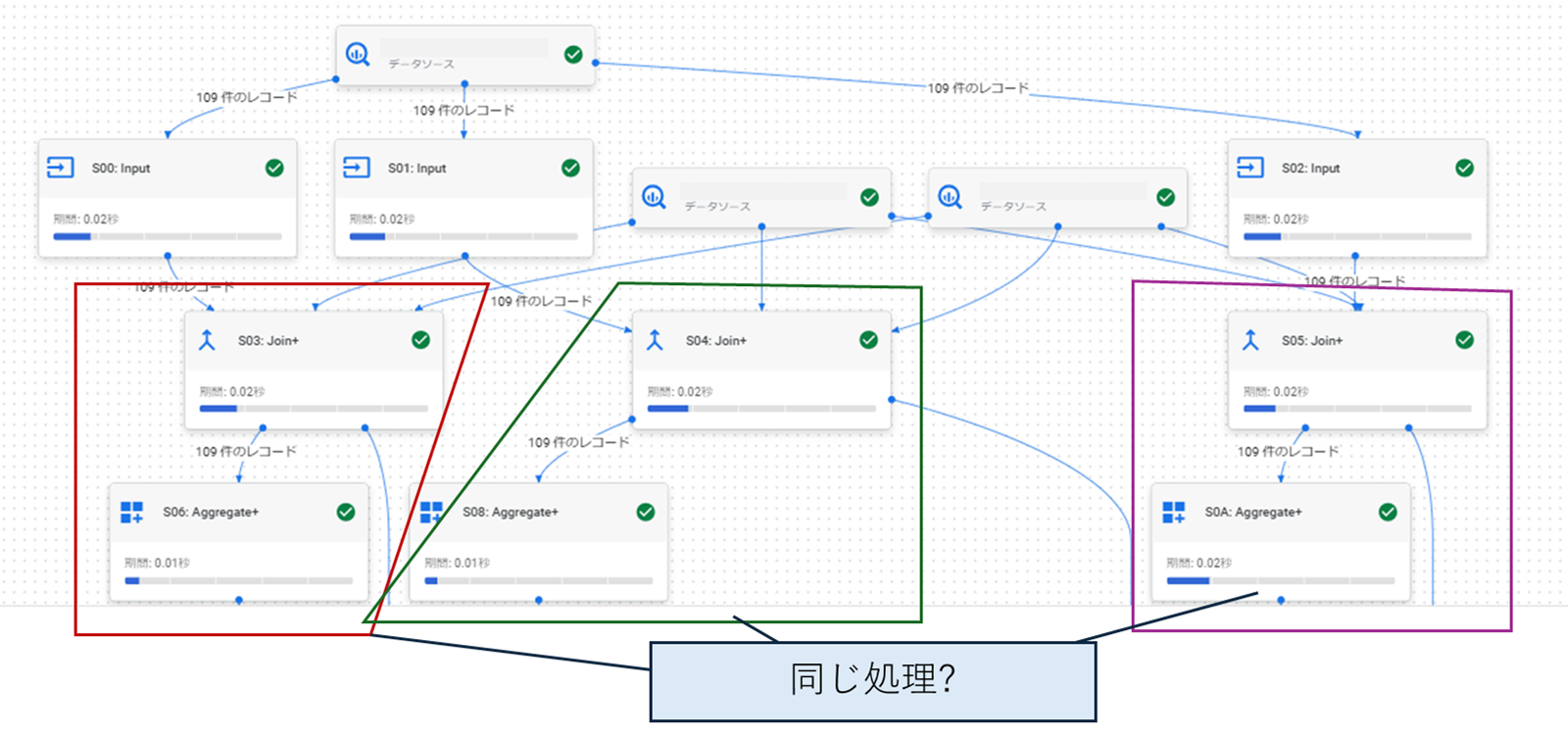
BigQueryのWITH句の説明には下記のような記述があり、参照されるたびにWITH句の処理が走ることが明記されています。
If a non-recursive CTE is referenced in multiple places in a query, then the CTE is executed once for each reference.
Google翻訳: 非再帰的 CTE がクエリ内の複数の場所で参照されている場合、CTE は参照ごとに 1 回実行されます。
そのため、複数箇所で参照するようなデータは一時テーブルに書き出すことでリソース消費の軽減に繋がります。 このことはGoogle Cloudのガイドにも記載があり、今回私が試した際にはCPUの使用量を半分くらいまで削減することができました。
ただし、オプティマイザーの結果や書きだしコストによってはWITH句のままの方がCPU使用量が低い場合もあるので、WITH句版と実際に比較してみると良さそうです。
JOINの条件をシンプルにする
JOINをする際にNULLも考慮して結合したかったため、下記のような書き方をしていました。
... ON COALESCE(t1.col1 = t2.col1, t1.col1 IS NULL AND t2.col1 IS NULL) AND COALESCE(t1.col2 = t2.col2, t1.col2 IS NULL AND t2.col2 IS NULL) ...
この部分を下記のように書き換えたところ、劇的に早くなりました。
※ col1やcol2に空文字が含まれる場合は結果が異なるので置き換える文字は適宜考える必要があります。
... ON IFNULL(t1.col1, "") = IFNULL(t2.col1, "") AND IFNULL(t1.col2, "") = IFNULL(t2.col2, "") ...
この件について、一般公開データセットのgithub_timelineを使ってもう少し深く検証してみます。
検証内容
下記の4つのパターンのSQLでスロット時間を比較してみました。
A. COALESCE関数内で処理
WITH actors AS (
SELECT DISTINCT
actor
FROM `bigquery-public-data.samples.github_timeline`
WHERE type = 'IssueCommentEvent'
)
SELECT
t1.repository_owner,
t1.actor,
t2.actor
FROM `bigquery-public-data.samples.github_timeline` AS t1
INNER JOIN actors AS t2
ON COALESCE(t1.repository_owner = t2.actor, t1.repository_owner IS NULL AND t2.actor IS NULL)
B. IFNULL関数内で処理
WITH actors AS (
SELECT DISTINCT
actor
FROM `bigquery-public-data.samples.github_timeline`
WHERE type = 'IssueCommentEvent'
)
SELECT
t1.repository_owner,
t1.actor,
t2.actor
FROM `bigquery-public-data.samples.github_timeline` AS t1
INNER JOIN actors AS t2
ON IFNULL(t1.repository_owner = t2.actor, t1.repository_owner IS NULL AND t2.actor IS NULL)
C. COALESCE関数で処理したものを比較
WITH actors AS (
SELECT DISTINCT
actor
FROM `bigquery-public-data.samples.github_timeline`
WHERE type = 'IssueCommentEvent'
)
SELECT
t1.repository_owner,
t1.actor,
t2.actor
FROM `bigquery-public-data.samples.github_timeline` AS t1
INNER JOIN actors AS t2
ON COALESCE(t1.repository_owner, "") = COALESCE(t2.actor, "")
D. IFNULL関数で処理したものを比較
WITH actors AS (
SELECT DISTINCT
actor
FROM `bigquery-public-data.samples.github_timeline`
WHERE type = 'IssueCommentEvent'
)
SELECT
t1.repository_owner,
t1.actor,
t2.actor
FROM `bigquery-public-data.samples.github_timeline` AS t1
INNER JOIN actors AS t2
ON IFNULL(t1.repository_owner, "") = IFNULL(t2.actor, "")
検証結果
各パターンを実行した結果、下表のようになりました。
関数内で処理した場合(A, B)と比較し、関数で処理したものを比較した場合(C, D)は大きくリソースを節約できました。 また、COALESCE関数に比べ、IFNULL関数を使った方が処理効率は良いようです。
| パターン | 経過時間 | 消費したスロット時間 |
|---|---|---|
| A | 31秒 | 8時間13分 |
| B | 22秒 | 7時間4分 |
| C | 4秒 | 16秒 |
| D | 3秒 | 15秒 |
考察
なぜこのような結果になったのか。それは実行グラフのJOINステップのステップ詳細を見るとわかります。
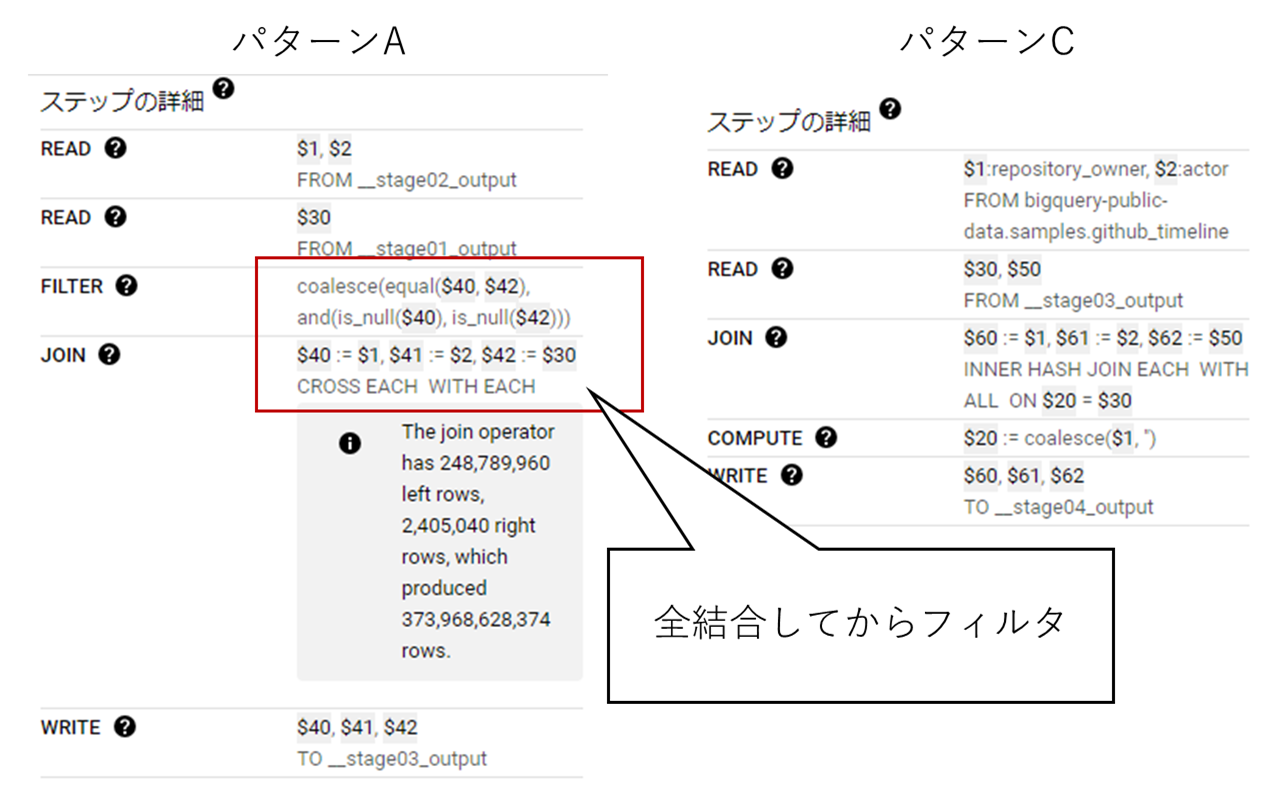
上図の通り、 関数内で処理する場合はJOIN時にCROSS EACHで全結合した後に条件にあった物をフィルタリングする流れになってしまいます。 それに対し、関数で処理したものを比較した場合は先に関数によって値を置き換えたテーブルを作成し、その後に特定カラムが一致するもののみを結合する流れになっています。
したがって、関数処理したものを比較する場合の方が処理するレコード数も処理ステップ数も少なくなり、リソースの効率化に繋がる訳です。
JOINのOR条件をUNION ALLで代用する
テーブルを結合する際、複数の条件を組み合わせて結合するケースがあります。 この時、ANDの組み合わせは処理量が減りますが、ORの組み合わせは処理量が増える傾向があります。ORを使う場合は、それぞれの条件で結合した後にUNION ALL等で繋ぎ合わせると良いです。
この件についても一般公開データセットのgithub_timelineを使って検証してみます。
検証内容
下記の4つのパターンのSQLでスロット時間を比較してみました。
A. 1つの条件で結合
WITH actors AS (
SELECT DISTINCT
actor
FROM `bigquery-public-data.samples.github_timeline`
WHERE type = 'IssueCommentEvent'
)
SELECT
t1.repository_owner,
t1.actor,
t2.actor
FROM `bigquery-public-data.samples.github_timeline` AS t1
INNER JOIN actors AS t2
ON
t1.repository_owner = t2.actor
B. OR条件で結合
WITH actors AS (
SELECT DISTINCT
actor
FROM `bigquery-public-data.samples.github_timeline`
WHERE type = 'IssueCommentEvent'
)
SELECT
t1.repository_owner,
t1.actor,
t2.actor
FROM `bigquery-public-data.samples.github_timeline` AS t1
INNER JOIN actors AS t2
ON
t1.repository_owner = t2.actor
OR t1.actor = t2.actor
C. UNION ALLで結合
WITH actors AS (
SELECT DISTINCT
actor
FROM `bigquery-public-data.samples.github_timeline`
WHERE type = 'PullRequestEvent'
)
SELECT
t1.repository_owner,
t1.actor,
t2.actor
FROM `bigquery-public-data.samples.github_timeline` AS t1
INNER JOIN actors AS t2
ON
t1.repository_owner = t2.actor
UNION ALL
SELECT
t1.repository_owner,
t1.actor,
t2.actor
FROM `bigquery-public-data.samples.github_timeline` AS t1
INNER JOIN actors AS t2
ON
t1.actor = t2.actor
D. ANDで結合(おまけ)
WITH actors AS (
SELECT DISTINCT
actor
FROM `bigquery-public-data.samples.github_timeline`
WHERE type = 'IssueCommentEvent'
)
SELECT
t1.repository_owner,
t1.actor,
t2.actor
FROM `bigquery-public-data.samples.github_timeline` AS t1
INNER JOIN actors AS t2
ON
t1.repository_owner = t2.actor
AND t1.actor = t2.actor
検証結果
各パターンを実行した結果、下表のようになりました。 Aを基準として比較すると、OR条件を使うパターンBは3倍近く処理量が増えていますが、UNION ALLのパターンCは1.5倍程度に収まっています。
なお、今回のUNION ALLのパターンでは1つ目の条件と2つ目の条件の両方にヒットするレコードは重複して返します。実際に使う時はDISTINCTを使って重複削除をしてください。
| パターン | 経過時間 | 消費したスロット時間 |
|---|---|---|
| A | 3秒 | 20秒 |
| B | 5秒 | 1分6秒 |
| C | 7秒 | 28秒 |
| D | 2秒 | 12秒 |
考察
こちらも実行グラフのステップ詳細を見てみます。
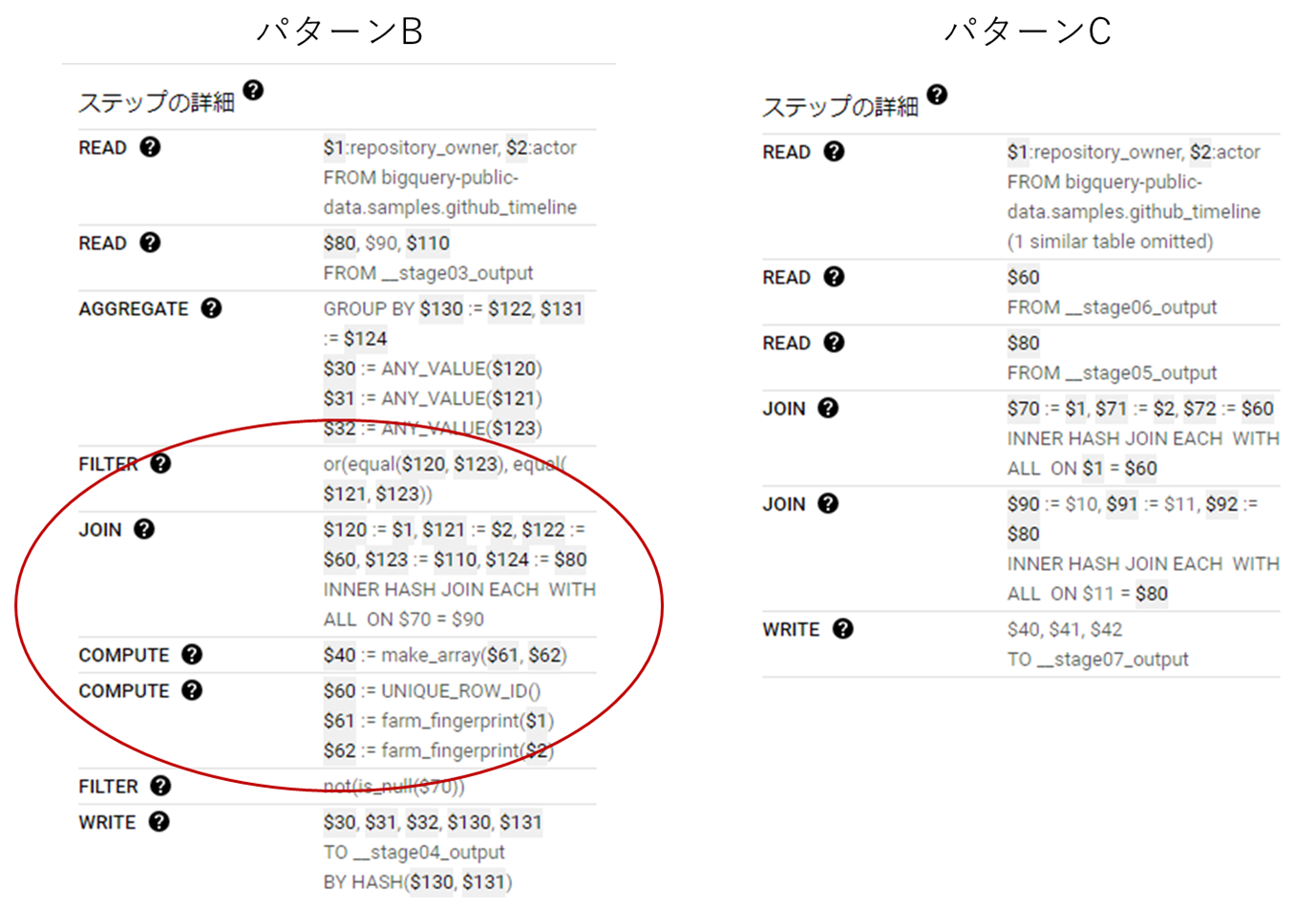
UNION ALL(右)の場合は2回結合してそれを繋いでいるだけなのでシンプルです。 しかし、ORの場合は2つのカラムの組み合わせのハッシュ値を求めてその値で結合し、その結果をフィルタリングするという複雑な処理過程になってしまっています。 そのため、処理するレコード数とステップ数が増加し、結果として処理時間が長くなってしまいます。
まとめ
実行グラフを見ながらBigQueryの最適化について検証してみました。 その結果、
- 複数箇所で参照する場合はWITH句ではなく一時テーブルを使ってみる
- JOIN時の条件は
○ = ×の形式になるようにする - JOIN時の条件に
ORを使うのは避ける
といった知見を得られました。 BigQueryであってもJOINをシンプルな形にするというSQLの基本は大切だということを実感できました。
最後に
自社に専門人材がいない、リソースが足りない等の課題をお持ちの方に、エンジニア領域の支援サービス(Data Engineer Hub)をご提供しています。 お困りごとございましたら是非お気軽にご相談ください。
本記事に関するお問い合わせは下記にて承ります。
株式会社DataCurrent
info@datacurrent.co.jp