2021.12.22 コラム
【テックコラム】Cloud Data Fusion で Amazon S3 のデータを統合
● はじめに
こんにちは、DataCurrentの笹沼です。
Google Cloud の Cloud Data Fusion を使用したデータ統合を行ってみたいと思います。
内容は、Amazon S3にある Book-Crossing Dataset を取得し、結合して BigQuery に出力する手順です。
● 目次
● Cloud Data Fusion について
Cloud Data Fusion は、エンジニアでなくともデータパイプラインを作成したい、開発者の稼働を省力化するサービスだと思います。
ELT で問題ないなら BigQuery DTS を利用する。ETL が必要な要件で Cloud Composer を使うより手軽にデータパイプラインを構築したい。そういった場面に Cloud Data Fusion が向いていそうです。
以下はGoogle Cloud からの引用です。
Cloud Data Fusion は、データ パイプラインを迅速に構築し管理するための、フルマネージドかつクラウド ネイティブなエンタープライズ データ統合サービスです。ビジネスユーザー、デベロッパー、データ サイエンティストは、インフラストラクチャに煩わされることなく、データのクレンジング、準備、ブレンド、転送、変換を行うスケーラブルなデータ統合ソリューションを簡単かつ確実に構築できます。
Cloud Data Fusion のドキュメントより引用
● 使用するデータ
本コラムでは Book-Crossing Dataset というパブリックデータセットを使用します。
Book-Crossing Dataset は本のレビューデータで、以下の3つのファイルがあります。
$ unzip BX-CSV-Dump.zip Archive: BX-CSV-Dump.zip inflating: BX-Book-Ratings.csv inflating: BX-Books.csv inflating: BX-Users.csv
それぞれのファイルの概要です。
- BX-Users.csv:278,858 人のユーザーデータ
- BX-Books.csv:271,379 冊の本データ
- BX-Book-Ratings.csv:1,149,780 件の本の評価データ
今回は上記のファイルをS3に格納しています。
$ aws s3 ls s3://<bucket-name>/book-crossing/BX-CSV-Dump/ 2021-12-15 08:26:45 30682276 BX-Book-Ratings.csv 2021-12-15 08:26:46 77787439 BX-Books.csv 2021-12-15 08:26:46 12284157 BX-Users.csv
データセットの詳しい内容は Cloud Data Fusion を使って見ていきたいと思います。
● Cloud Data Fusion
では、利用するサービスとデータの整理ができたので、Cloud Data Fusion を操作してみます。
今回のデータ統合は、
取得(Source)
- 変換(Transform)
- 分析(Analytics)
- 出力(Sink)
という流れで行います。
事前に以下を参考にインスタンスを立ち上げます。20分ほどかかるかと思います。
【Source】
最初はSourceの設定を行います。
インスタンス作成後、Cloud Data FusionのUIを開きます。下記の画面になるので Wranglerを選択します。
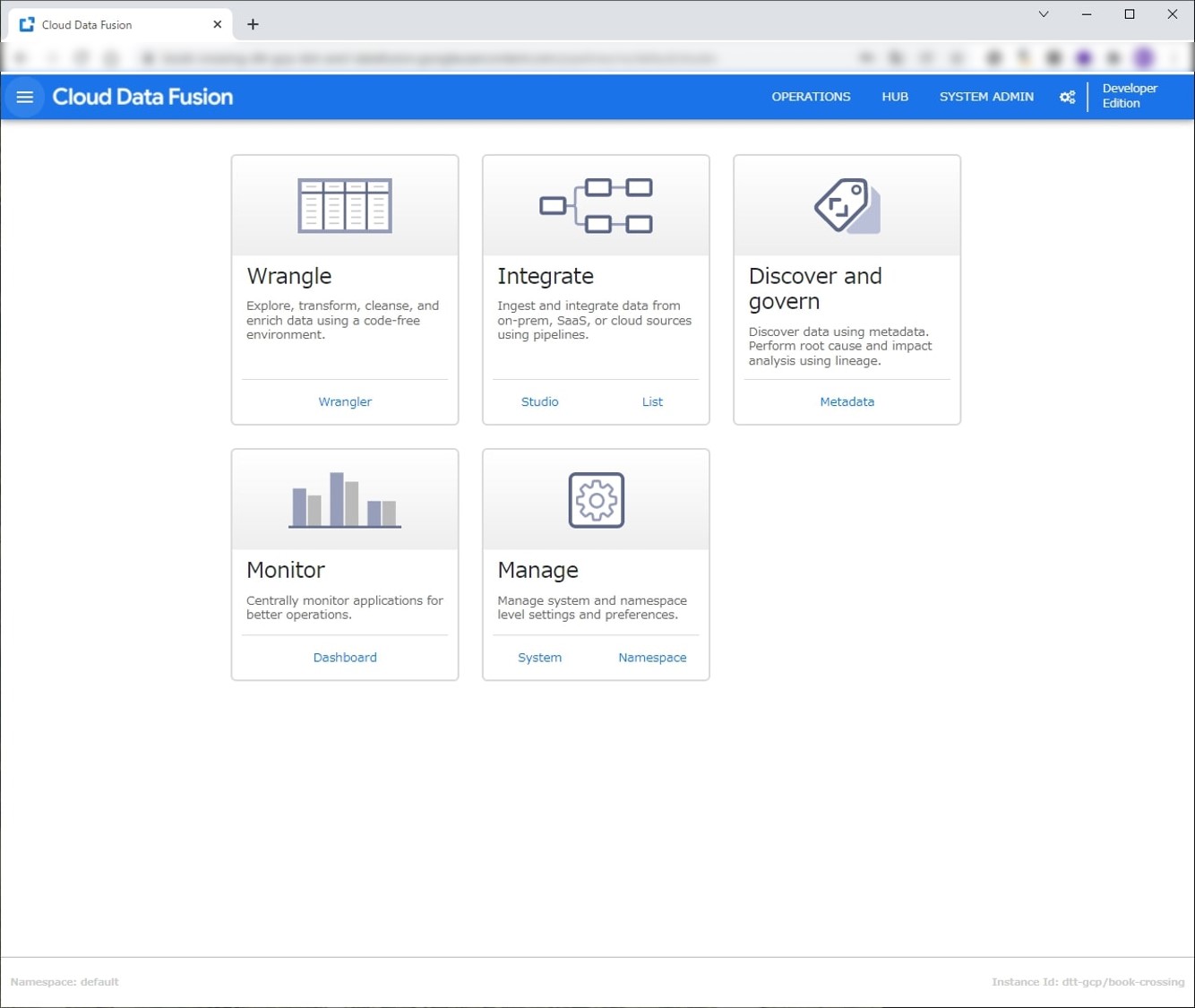
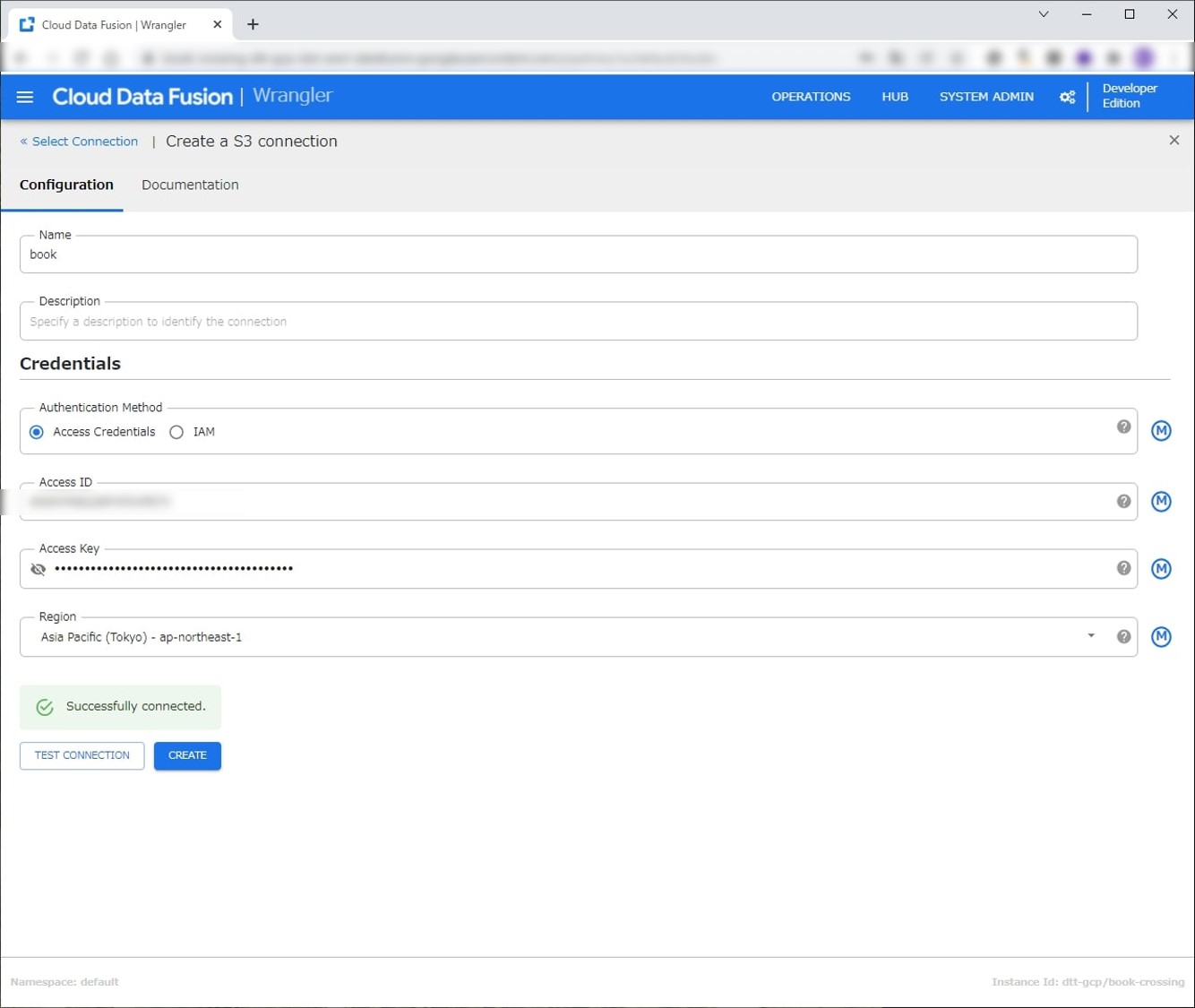
WranglerからS3とのコネクションを設定します。
名前はbookにしています。AWSのIAMで作成したアクセスキーとシークレットキーを入力します。
以降は同じバケットにアクセスする際にこのコネクションを選択できます。
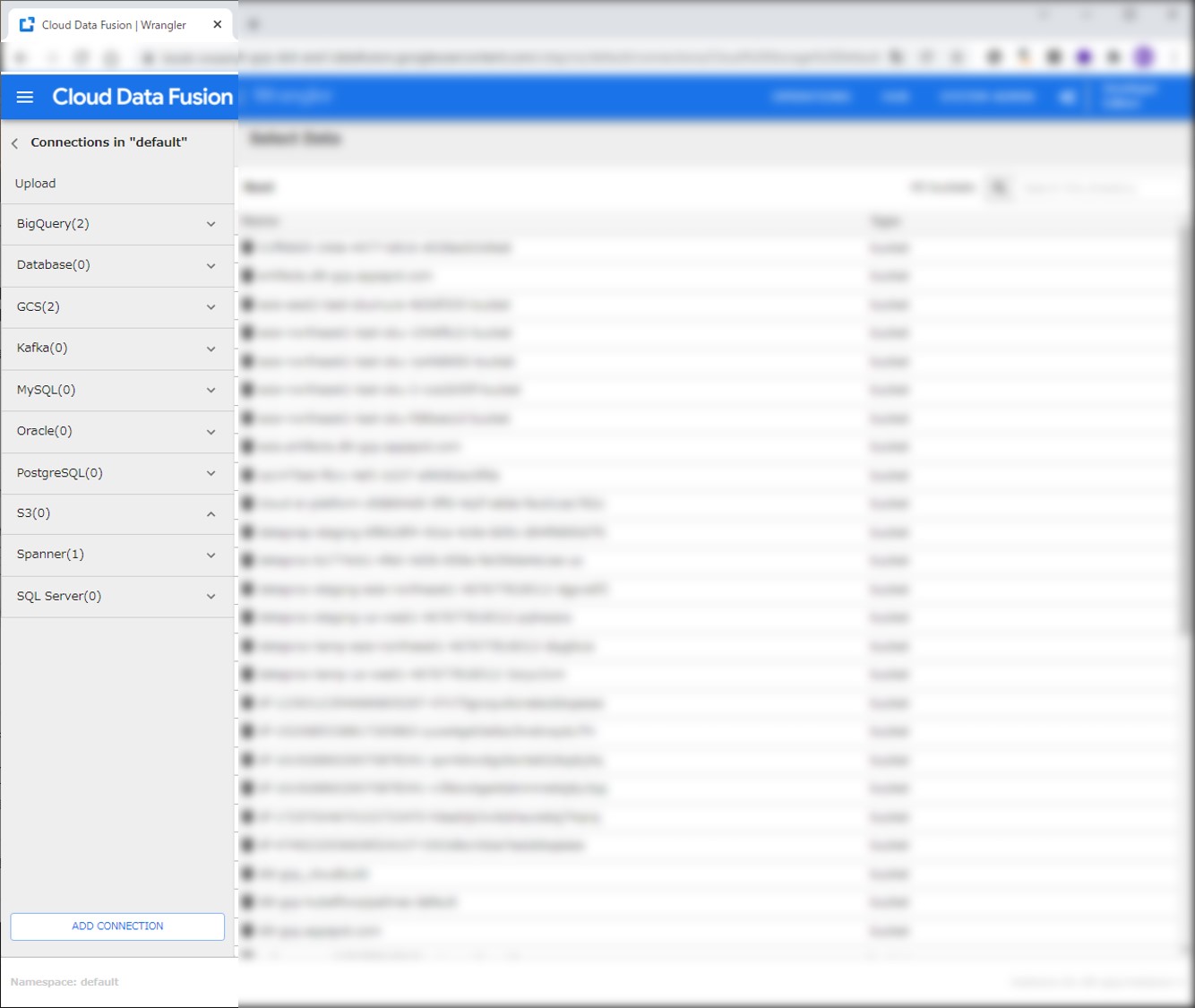
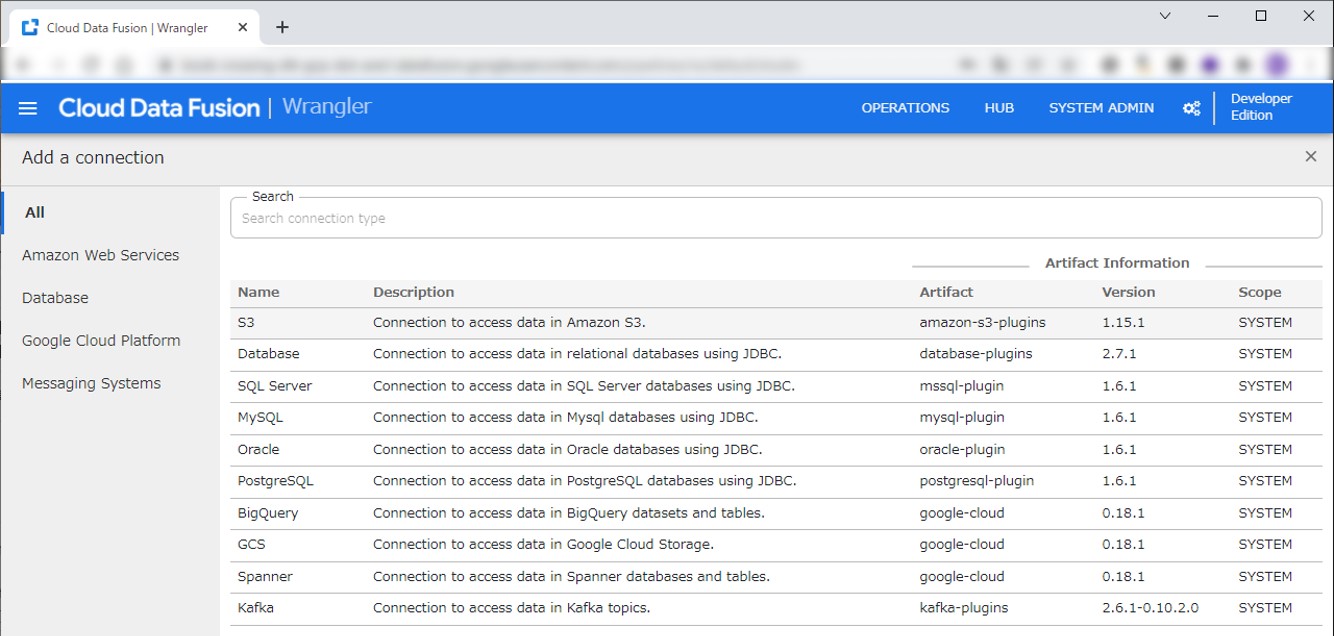
コネクションが設定できたら、S3からデータを取得します。ブラウズして取得したいファイルを選択します。
まずはBX-Books.csvを選択しました。
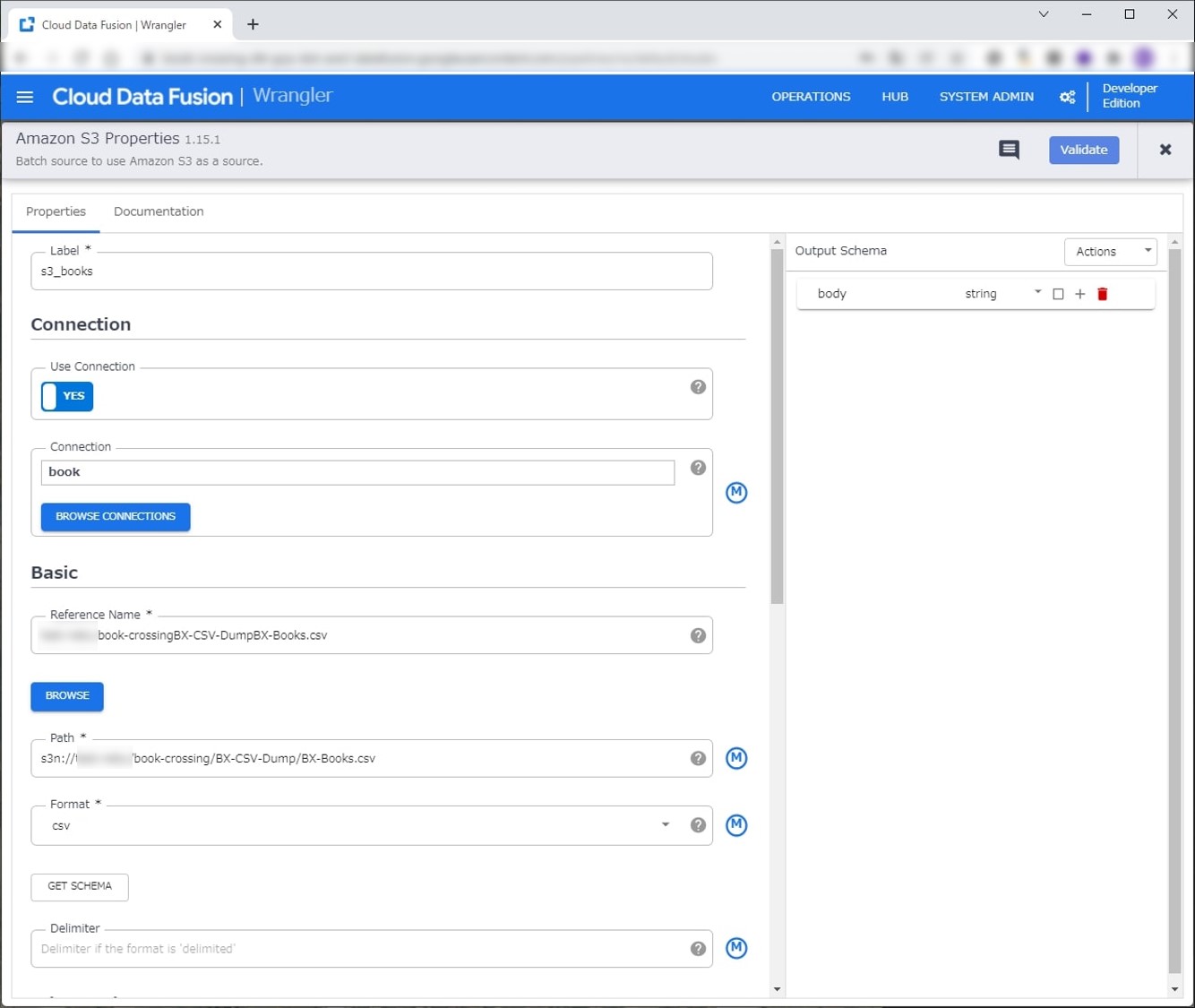
選択後、Amazon S3のSource画面に遷移します。各入力フォームに値が自動保管されている状態になっています。
Pathの部分ですが、先頭が s3n:// になっていると思います。これを s3a:// に変更してください。
くわしくは こちら にありますが s3n:// だとデータが取得できないので気を付けてください。
【Transform】
Sourceの設定が完了したので、次はTransformを行います。
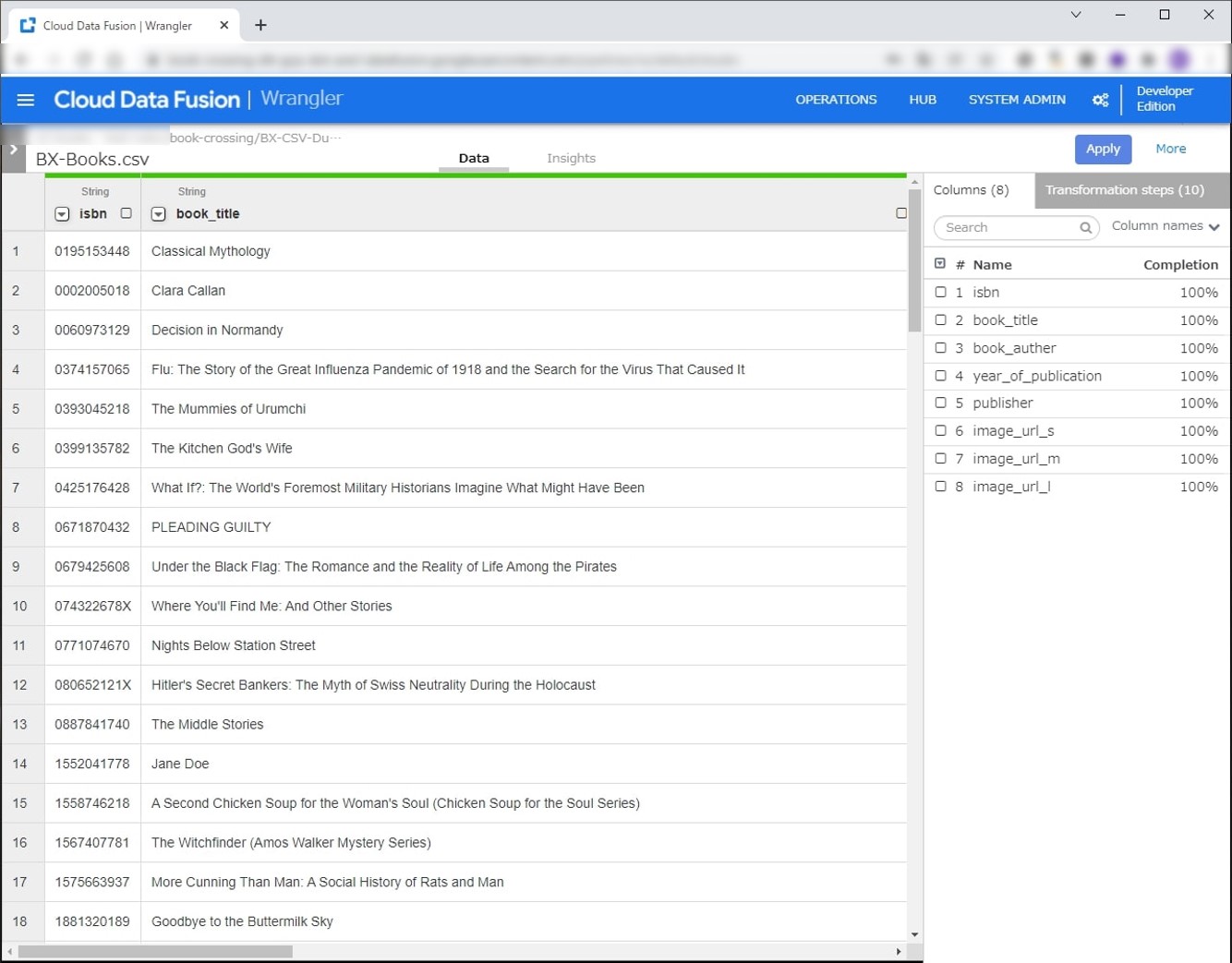
本データの区切り文字はセミコロンになっています。BigQueryにデータをエクスポートするので、カラム名のハイフンをアンダースコアに置き換えています。ついでに大文字も小文字に直しました。
Transformation stepsの内容は以下です。
- parse-as-csv :body ‘;’ true
- drop :body
- rename ISBN isbn
- rename Book-Title book_title
- rename Book-Author book_author
- rename Year-Of-Publication year_of_publication
- rename Publisher publisher
- rename Image-URL-S image_url_s
- rename Image-URL-M image_url_m
- rename Image-URL-L image_url_l
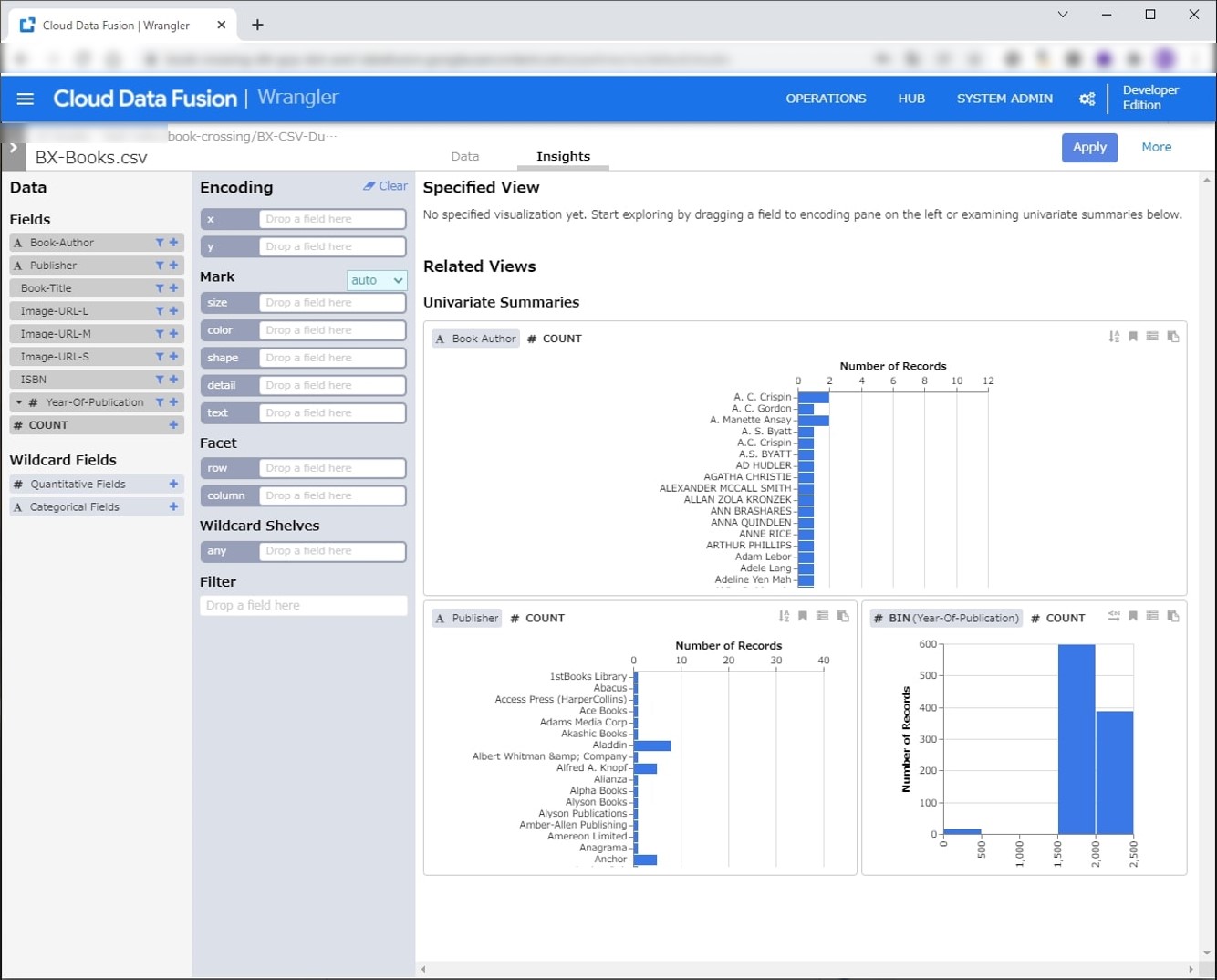
Insightsではデータの概要を見ることができます。
1000件のサンプリングになりますが、データを雰囲気を把握することができます。2000年付近の出版が多いですね。
画像だと Apply になっていますが、Create Pipeline のボタンを押すと下記の Pipeline が作成されます。
今回 Wrangler の Error Handling は Skip error に設定しています。
上記の工程をUsersとratingsにも行います。
以降はTransformタブからWranglerを選択してS3からデータ取得を行います。
左のSourceタブから Amazon S3 を選択して操作するより、Wrangleボタンから操作するほうが簡単だと思います。Wrangleでコネクションを選択できます。
これでS3からデータを取得する部分の実装が終わりました。
【Analytics】
Transformが完了したので、次は Analytics を行います。結合の手順は 2 つのデータソースを結合する を参考にしてデータのJoinをします。
BooksとRatingsのデータをISBNをキーに結合します。AnalyticsタグからJoinerを選択します。
先ほど作成したBooksのWranglerとRatingsのWranglerをJoinerに紐づけます。JoinerのPropertiesを押して設定をします。
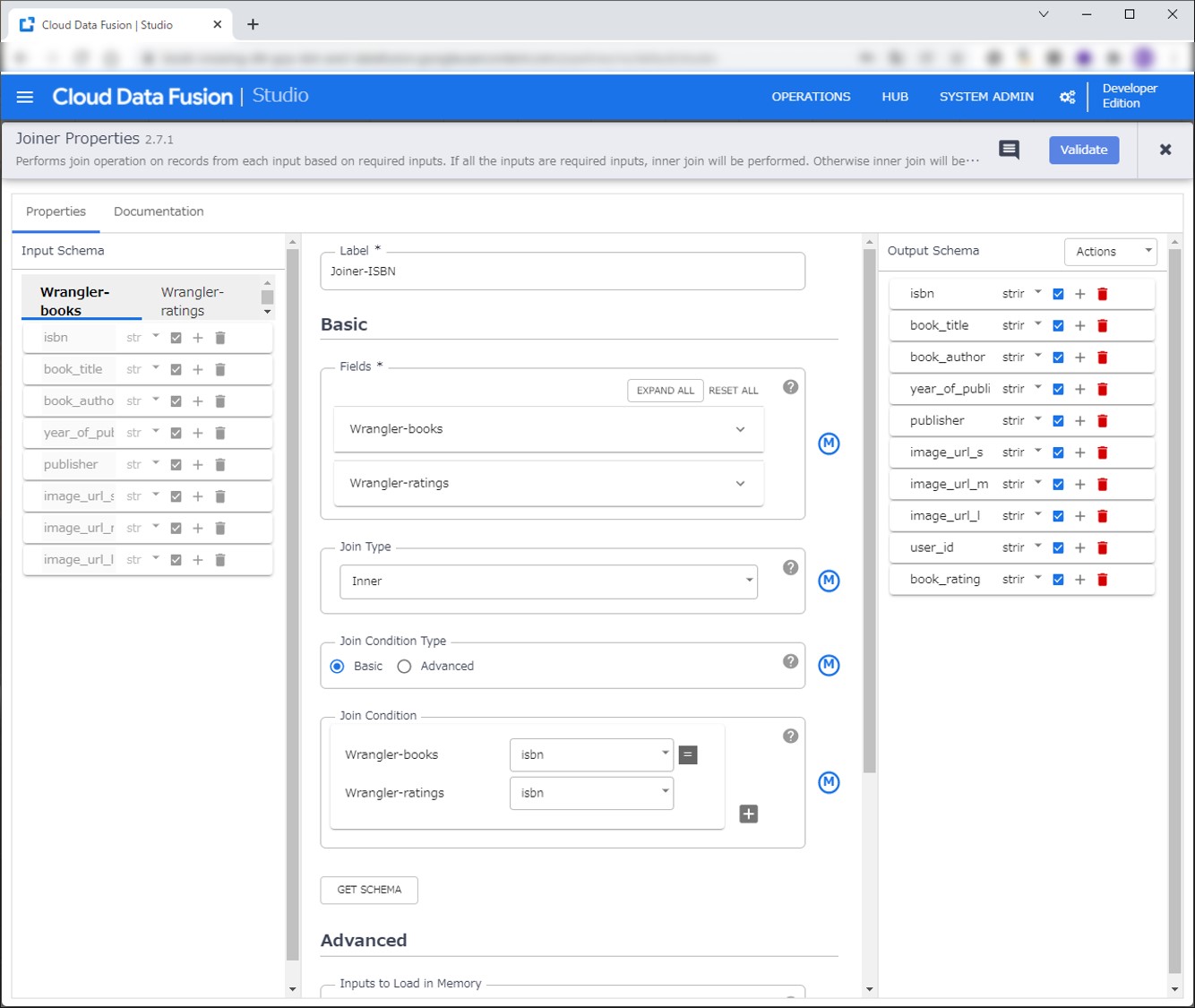
今度は先ほどJoinerの結果とUsersのデータを結合します。user_idをキーに結合します。
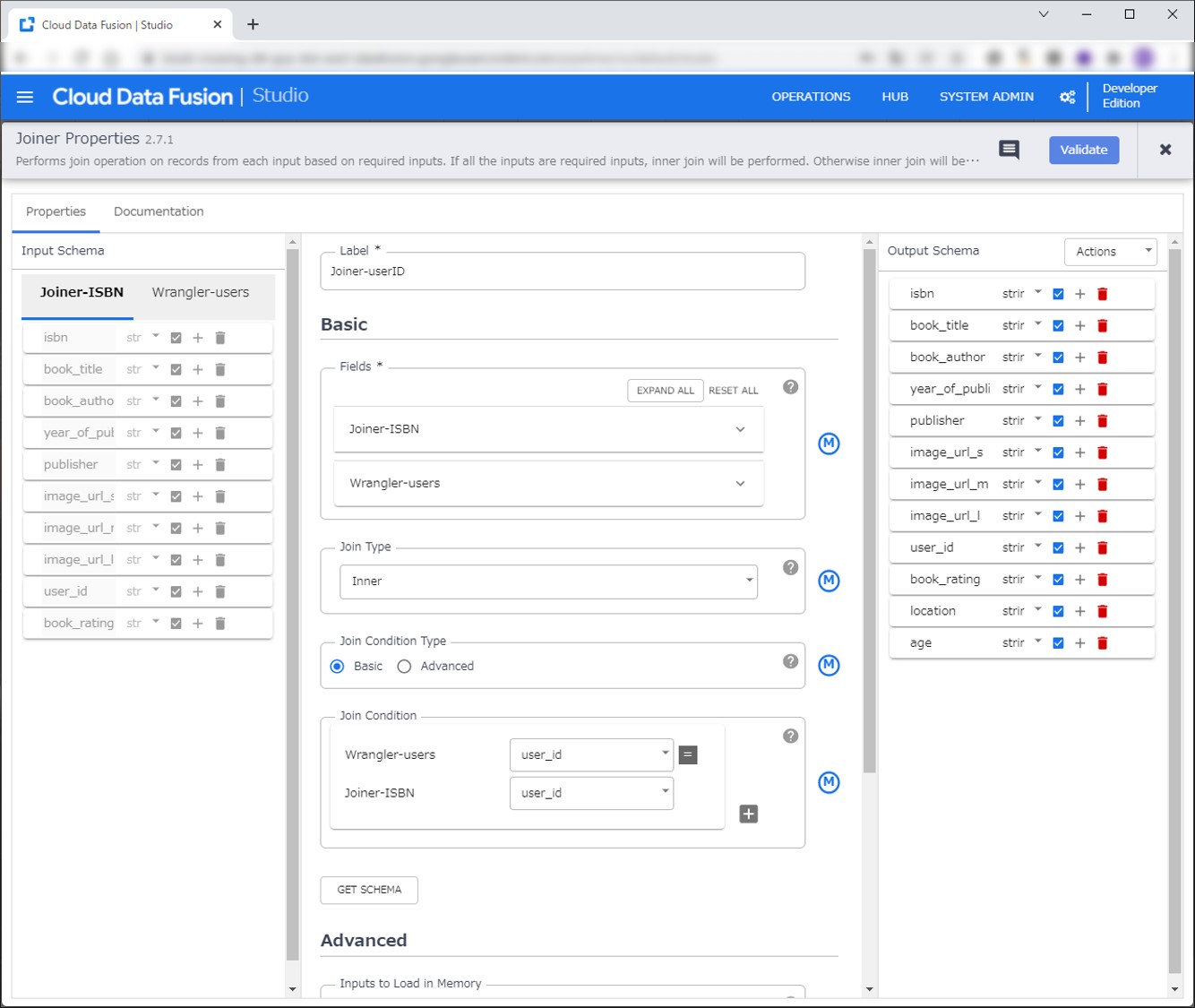
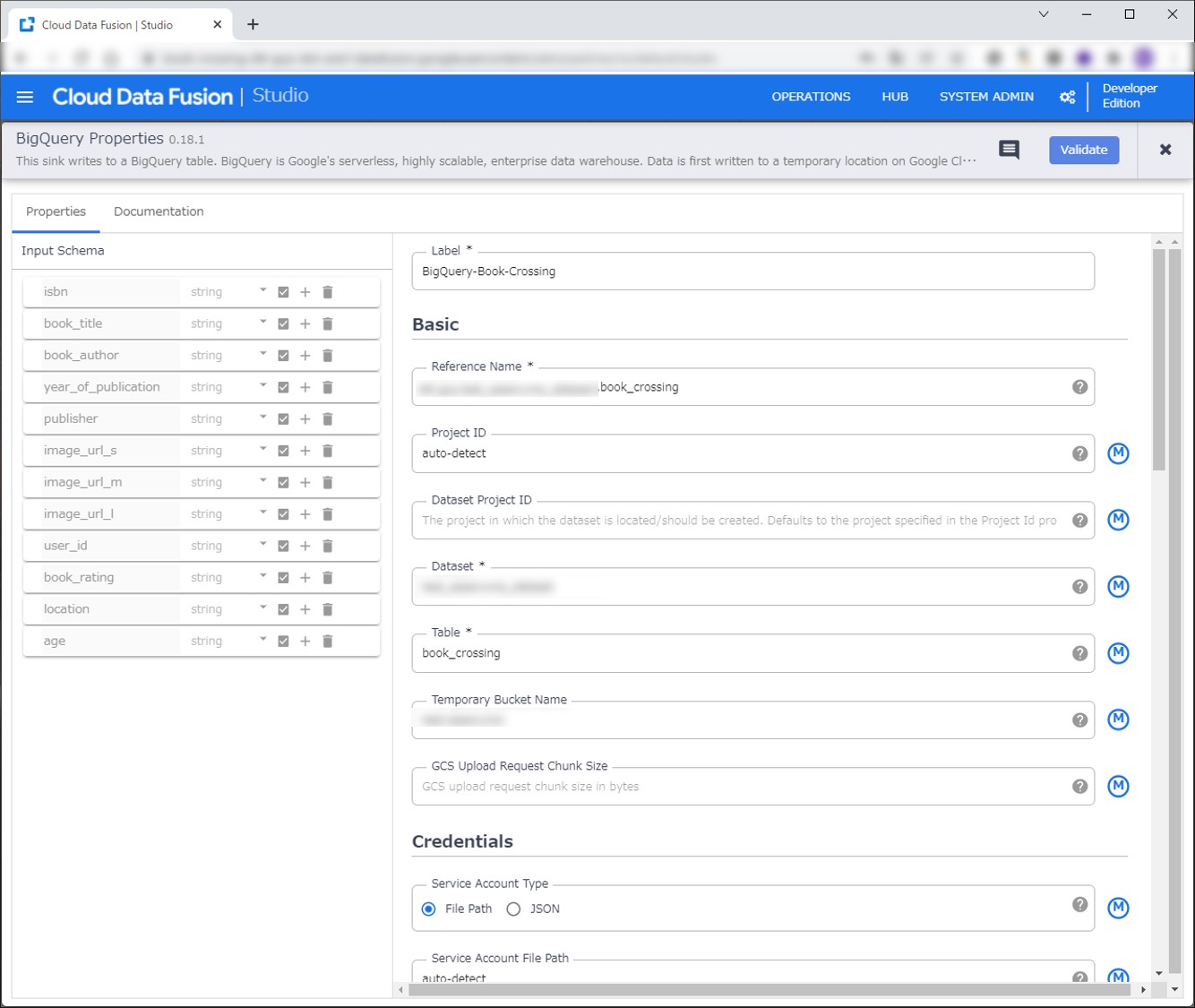
【Sink】
最後にSinkを行います。左のタブからSinkからBigQueryを選択します。
Output Schemaのカラム名にハイフンがあるとエラーになるので Transform でカラムをリネームしてください。
【Pipeline】
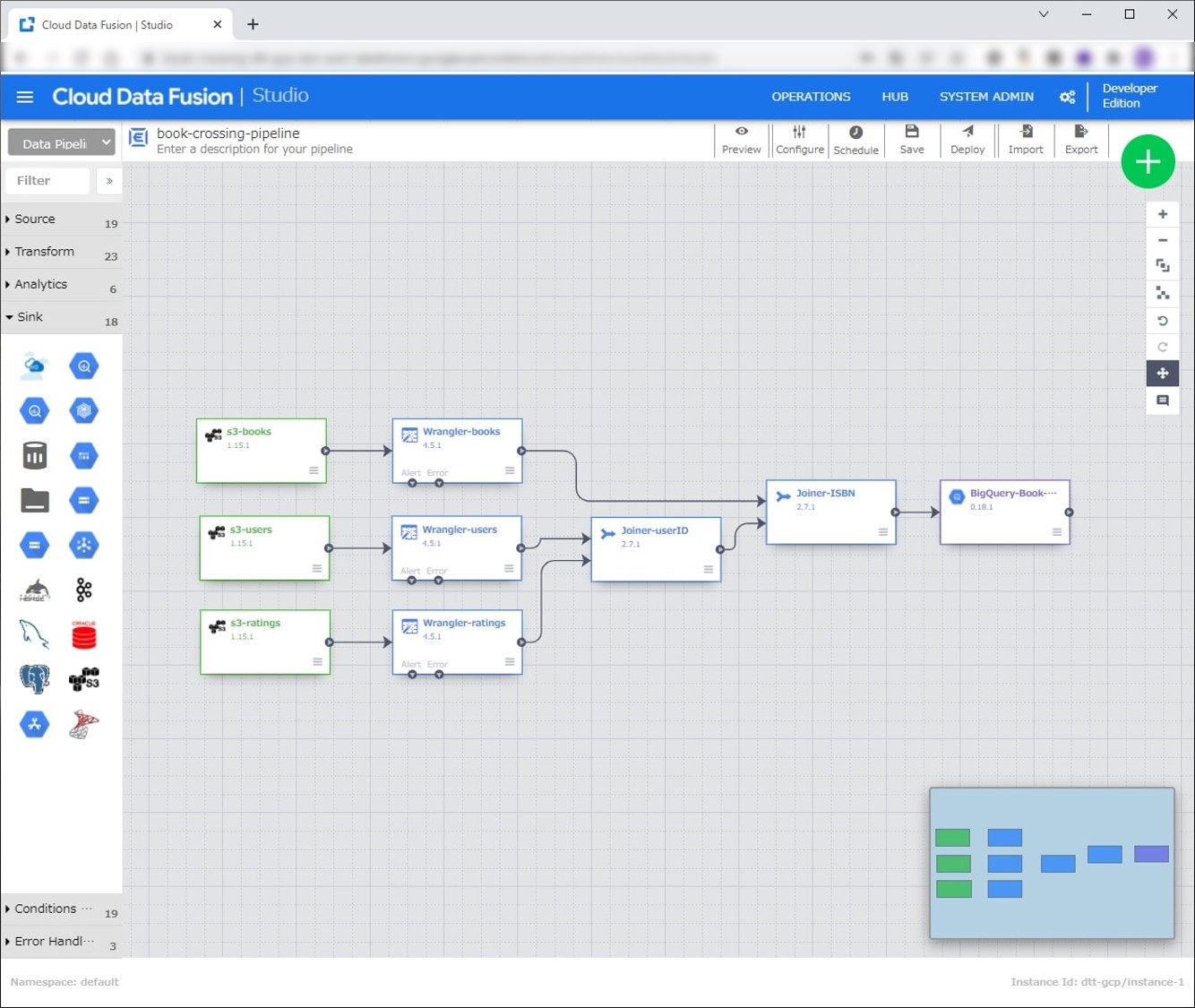
上記手順が終わると以下画像のデータパイプラインが作成されています。
右下にあるミニマップを見ると緑色のExtract、青色のTransform、紫色のLoadでETLになっていそうですね。
上のメニューからPreviewから実行して問題なければDeployを押します。
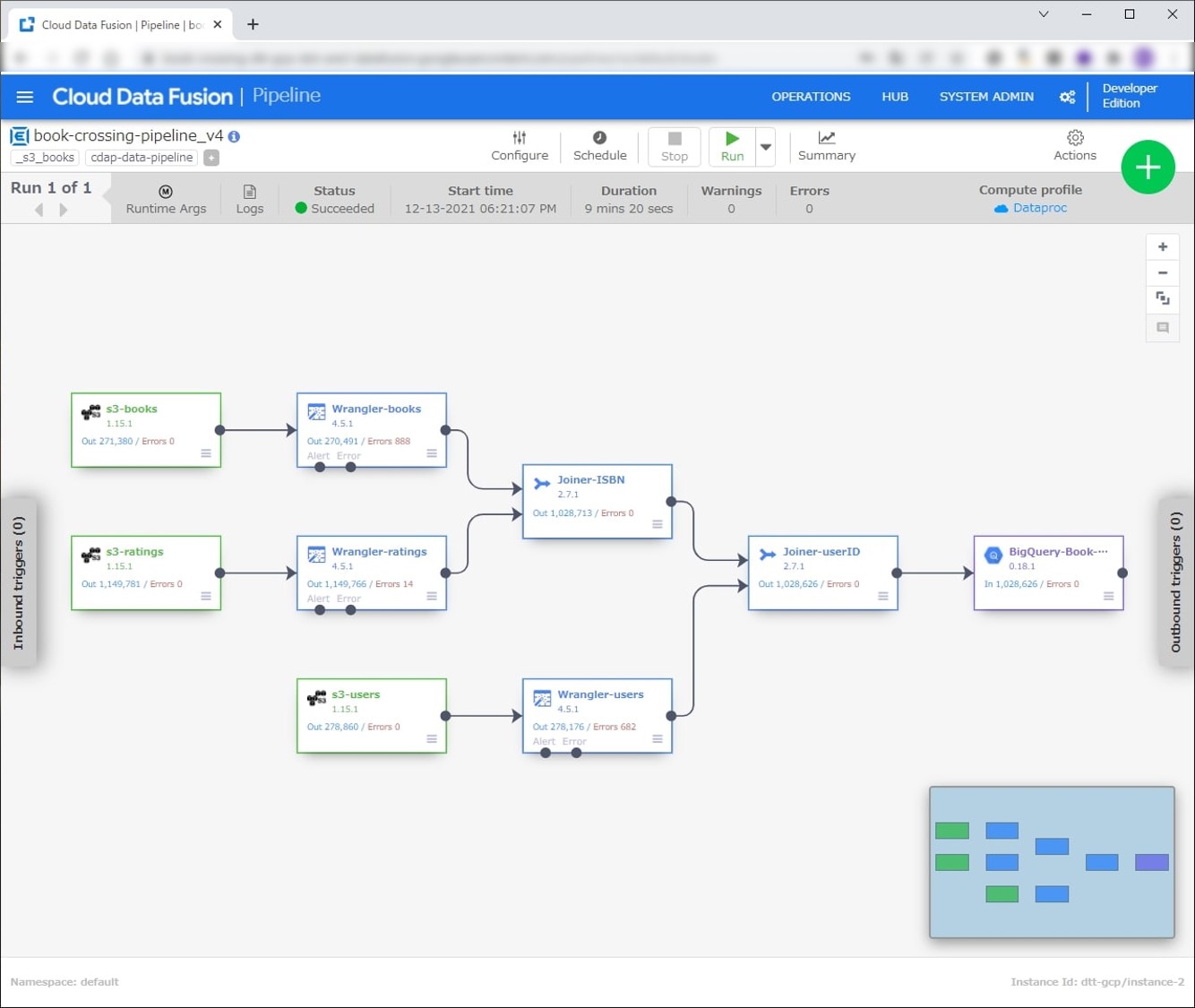
Deploy後、Pipelineを実行します。Runを押すと実行が開始されます。10分程度で終わると思います。
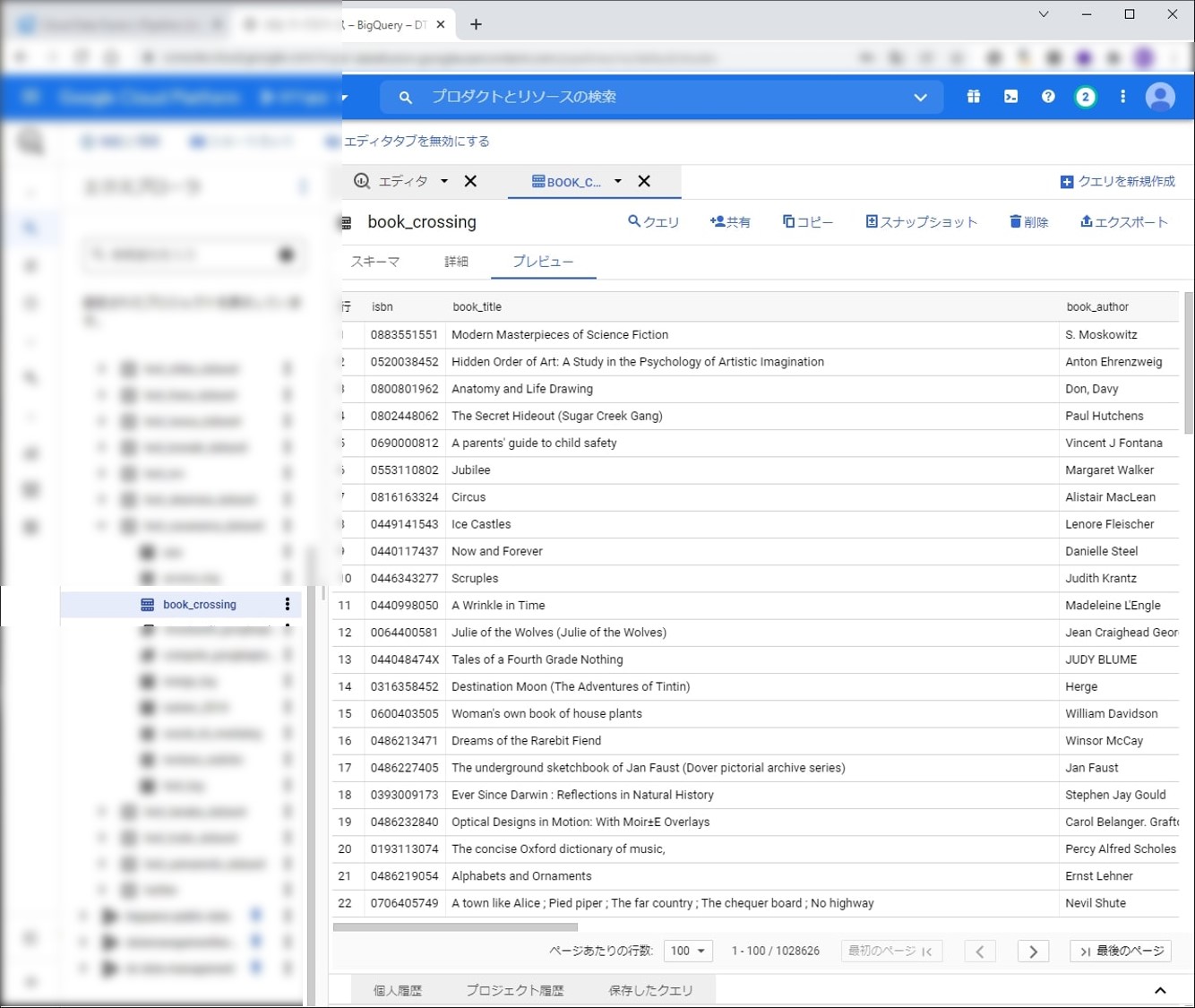
【BigQuery】
実際に、BigQueryのテーブルを確認してみます。S3にあったファイルがデータ結合されてBiqQueryに格納されています。
● おわりに
Cloud Data Fusionでデータパイプラインの作成を行いました。
データ連携するのにエンジニアの手を借りていた状態から、Cloud Data Fusionを使うことで、自分でデータパイプラインを作成し、データ分析を行える基盤を構築するのが容易になったと思います。
エンジニアとしても開発工数の削減や運用面で楽できるので、コーディングが必要な開発に専念できるようになると思います。
自社に専門人材がいない、リソースが足りない等の課題をお持ちの方に、エンジニア領域の支援サービス(Data Engineer Hub)をご提供しています。
お困りごとがございましたら、是非お気軽にご相談ください。

本件に関するお問い合わせは下記にて承ります。
株式会社DataCurrent
info@datacurrent.co.jp
本件に関するお問い合わせは下記にて承ります。
株式会社DataCurrent
info@datacurrent.co.jp