2025.07.24 コラム
BIツールでのダッシュボード開発におけるルールメイクのポイント【Looker編】
はじめに
Lookerによるダッシュボード開発が定着しはじめ、開発ユーザーが増えてくると以下のような課題を感じることはないでしょうか?
・「人によって命名やロジックがバラバラで、毎回レビューや修正に余計な時間がかかる」
・「作った本人しか中身が分からず、属人化して引き継ぎや改修が滞りがち」
・「ダッシュボードやViewが乱立し、どれが最新かわからない、触るのが怖い」
こうした“属人化”や“ルール不在”が進行すると、
・ダッシュボードごとに数値や定義がズレて利用が進まなくなる
・作成者が異動・退職したとたんに「ブラックボックス化」する
・ちょっとした修正に想定以上の工数がかかる
など、データ活用そのものの推進力が大きく損なわれてしまいます。
そのため「今すぐにでも、“脱・属人化”を実現するルール策定が必要だ」と感じている方も多いのではないでしょうか。
本記事では、Looker開発現場で“実際に役立ったルールメイクのポイント”と、「失敗しないルール運用のコツ」をご紹介します。
Looker開発におけるよくある課題
Lookerを活用している多くの企業が、開発ユーザーの増加や組織拡大に伴い、下記のような課題に直面しています。
| 課題 | 発生する問題 | 結果 |
|---|---|---|
| 人によってLookMLの書き方がバラバラ | ・同じ売上データでも「amount」「sales_amount」など表現が統一されず、ユーザーが混乱 ・他者の開発物のレビューや修正のたびに理解し直しが必要 | 改修・レビュー・引き継ぎにコストの増大と属人化の加速 |
| 誰が何のダッシュボードを開発しているか分からない | ・誰がどこを担当しているか把握できないため、作業進捗の管理遅延やレビュー漏れが発生 ・複数人で同じViewやExploreを同時に編集することで、 コンフリクトや上書きミスが発生 | 重複開発や仕様のズレによる手戻りが頻発 |
| 開発が増えてきてView・Exploreが乱立し管理が大変 | ・似たようなViewが乱立して、どれが最新かわからず誰も触れなくなる ・モデルファイルが肥大化し、他の定義への影響範囲が読めず「壊しそうだから触れない」という状態に陥る | ユーザーの混乱・信頼低下、メンテナンス不能なモデル構成になる |
こうした状況で「とりあえずルールを作ったが、現場に定着しない」「データ・指標追加などのたびに混乱が起きる」といった“ルール策定の落とし穴”も多く見られます。
役立ったルールメイクのポイントと失敗しないルール運用のコツ
こうした“ルール策定の落とし穴”を避けるために、“実際に役立ったルールメイクのポイント”と「失敗しないルール運用のコツ」を、今回は3点ご紹介いたします。
①LookMLの命名規則を設ける
課題:人によってLookMLの書き方がバラバラ
上記の課題に対してはディメンションやメジャー等に「LookMLの命名規則を設ける」ことで、
・誰が書いても同じ構造・命名になり、チーム開発がスムーズになる
・一目でそのLookMLが何を意味するかが分かり、フィールド検索や再利用がしやすくなり、開発効率・品質が向上
といった効果が期待できます
一例としてViewファイル内でのディメンションとメジャーにおける、命名規則例をご紹介いたします。
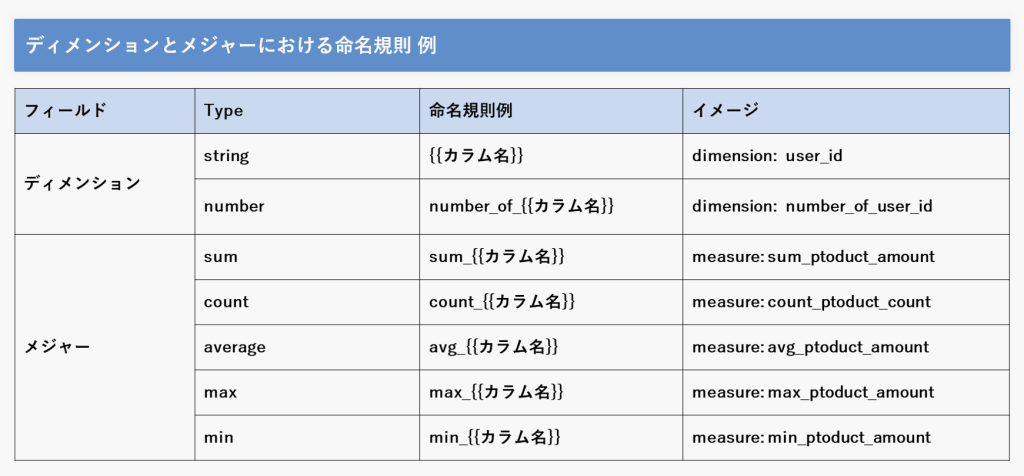
LookMLでは英語でしか名前を付けられないため、「labelパラメーター」で日本語名をつけることでよりLookMLの透明性を上げることができます。
また、ディメンションとメジャー以外にも「View」「Explore」「LookMLDashboard」へも命名規則を設けると、開発時の効率化や管理の効率化も期待できます。
②ブランチの運用ルールを設ける
課題:誰が何のダッシュボードを開発しているか分からない
上記の課題に対しては、ブランチの命名規則やブランチを作成するタイミング等「ブランチの運用ルールを設ける」ことで、
・誰が・何の目的で・どこを開発しているかが、ブランチ名で一目でわかり、開発の可視化と管理の効率化に繋がる
・開発ブランチが明確に分けることで、同じViewやExploreを複数人が同時に編集してコンフリクトするリスクが減る
といった効果が期待できます
今回は「GitHubFlow」の運用元にご紹介します。
【ブランチの作成タイミング】
1タスク1ブランチを原則として作業を行う
新規開発や、データソースの修正、ディメンション・メジャーの定義の修正など、開発タスクごとに作業ブランチを作成して作業を行うことで、何の開発作業をしているかを把握しやすくなります。
1タスクごとに変更範囲が限定されるため、レビューがしやすくなるといった点や、
タスクの進捗や履歴が追いやすく、万一バグがあった場合でもすぐ変更点を確認できるといった点から、1タスク1ブランチで運用が有効とされます。
【ブランチの命名規則】
feature_\<作業開始日>_\<担当者名>_-\<内容>
例)リリース済みのダッシュボードへデータソース(View)を追加する改修開発を実施する場合
feature_20250501_datacurrent_add_view
上記フォーマットで作業ブランチに命名規則を設けると、いつ・だれが・何を・何の目的で開発しているのかが分かりやすくなります。
※featureブランチ:新規機能開発やバグ修正などの一時開発用ブランチ。mainブランチから作成する
③プロジェクト作成のルールを設ける
課題:開発が増えてきてView・Exploreが乱立し管理が大変
上記の課題に対しては、Lookerの最上位の単位にあたる「プロジェクト作成のルールを設ける」ことで、
・データソース単位に分けてプロジェクトを作成することで、View/Exploreのスコープが限定され、乱立を抑制できる
・開発対象がプロジェクト単位で明確になるため、作業分担・管理が明確にでき、プロジェクトの肥大化・複雑化を防げる
といった効果が期待できます
Lookerの最上位の単位にあたるプロジェクトについては、基本は1接続ごとに1つのプロジェクトを作成することが推奨されています。
よってデータソースが分かれる場合は、それぞれでプロジェクトを作成します。
しかし、同じデータソース内に複数データがまとまっているケースもあるかと思います。
その場合は、可視化したいデータごとにプロジェクトを作成して開発を進めることを推奨します。
例)ECサイト運用企業の場合
アパレルカテゴリー配下でレディース/メンズ/キッズカテゴリーに分かれてデータが管理されている場合、3つのプロジェクトを作成し開発を進める。
Lookerの権限管理においてはモデル単位でアクセス権の設定が可能となっています。
加えて、データセット単位など細かくアクセス権の設定が可能になっており、複数の権限を組み合わせて柔軟に権限の設定ができます。
プロジェクトは1つとし、モデルを分けて管理・開発を進めることも可能ですが、
1プロジェクト内でそれぞれのモデルに対する権限を持っているものと持っていないものが混在する場合、権限管理が複雑になるため、「1プロジェクト1モデル」とし、可視化したいデータごとにプロジェクトを作成して開発を進めることを推奨します。
さいごに
今回は、Looker開発現場で“実際に役立ったルールメイクのポイント”と、「失敗しないルール運用のコツ」をご紹介させて頂きました。
これから開発ルールの策定を検討している方の参考になれば幸いです。
また、DataCurrentではLookerの導入から社内浸透・活用までにおける一気通貫したサポートも実施しております。
・既存ルールが形骸化してきた
・開発ユーザーが増え管理が追いつかない
・そもそもどこから手をつければよいか分からない
といったお悩みをお持ちの方は是非お気軽にお問い合わせください。
■関連記事
・https://www.datacurrent.co.jp/documents/looker-20250310/
・https://www.datacurrent.co.jp/column/looker_ai_20250117/
本件に関するお問い合わせは下記にて承ります。
株式会社DataCurrent
info@datacurrent.co.jp