2022.03.23 事例
CDP活用事例 機械学習による休眠予測 <後編>
はじめに
私は普段、CDPを活用したデータ分析及び、施策立案の支援に従事しています。
クライアントの業態や業種によって、抱えている課題は様々あり、CDPを活用した分析・活用パターンも多岐にわたります。
前回はCDP活用事例 機械学習による休眠予測 <前編>としてTreasureDataのHivemallを使って実際に機械学習の予測モデルを作成した事例をご紹介しました。
今回はその事例にもう少し踏み込んで、機械学習をする際のコツや考え方等に触れていきたいと思います。
▽この記事はこんな方におススメ
- CDPの導入を検討しているけど、どんなことが出来るのか情報収集をしている
- CDPを導入したけど、うまく施策に活かせていない
- CDPを使って機械学習をしてみたい
目次
1.CDPで機械学習をする際の全体的な流れ
2.CDPでデータの集計・加工をする
3.CDPで機械学習を実行する
4.予測モデルの精度を評価する
5.まとめ
CDPでの機械学習の全体的な流れ
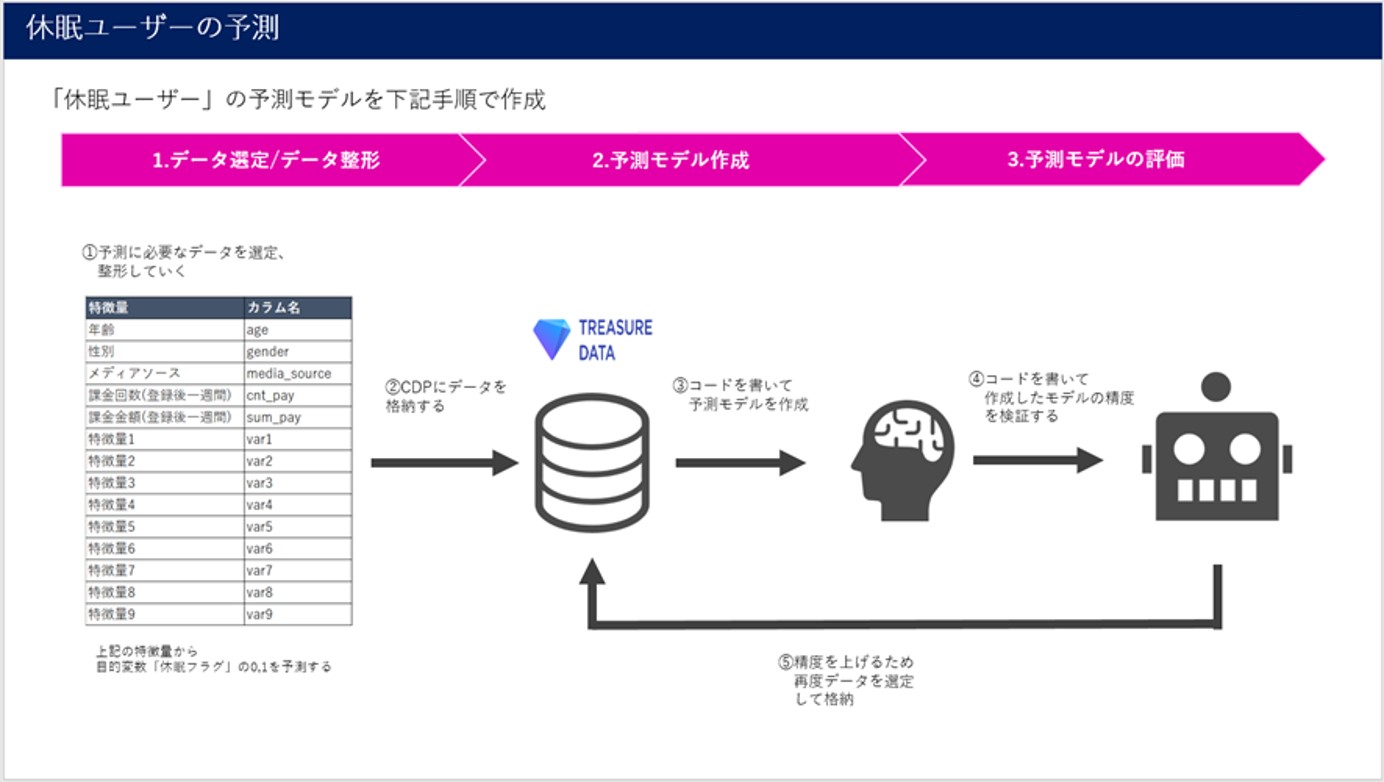
CDPで機械学習(二値分類)をする際の大きな流れとして以下の3つのステップに分かれます
- データを集計・加工する
- CDPで予測モデルを作成する
- 予測モデルの精度を評価する
まずCDP上で目的変数と説明変数に当たるデータを集計・加工します。予測モデルの精度に関わるのでこの工程はとても大切な工程となります。
その後先ほど集計したデータセットをCDP上で学習させ、予測モデルを作成します。
作成された予測モデルの精度を確認し、精度がいまいちだった場合はもう一度、データ集計・加工の工程に戻りデータセットの修正をし、機械学習・評価の工程を繰り返します。
CDPでデータを集計・加工する
二値分類の予測モデルを作成するといっても、何もないところから作成はできません。実際のデータを基に学習をして予測モデルを作成することになります。なのでまずは、予測したい目的変数のデータと、目的変数に影響しうる説明変数のデータを用意します。
先ほども触れた通りこの工程が予測モデルの精度に関わるとても大切な工程となります。
ではどのようなデータを説明変数に選定すればよいのでしょうか?それは予測したいデータによって全く違うので一概には言えませんが、データ集計の際のコツとして以下の2点があります。
しっかりと仮説をもってからデータを集計する
何が目的変数に影響しているかわからないので、とりあえず全部の説明変数を持ってくればよいという考え方に至る場合もあるかもしれませんが、必ずしも正しい選択ではありません。
説明変数が多すぎると予測モデルを解釈する時に大変な場合や、説明変数の数に比べデータ数が少なく十分な予測精度が得られない場合があります。
もしくは、説明変数の種類が増えると説明変数間での多重共線性が発生する可能性が高くなります。多重共線性が発生するとモデル内の説明変数の係数が不安定になり、どの説明変数が予測にとって重要かという情報が信頼できなくなります。(今回の事例の場合、Xgboostを採用したので共線性はあまり考慮しなかったが、ロジスティック回帰などを使う場合は考慮が必要になる。)
以上のようなリスクがあるので、どういう説明変数がユーザーの休眠に影響するかを予め仮説を立ててそれを検証するのが大切になります。
もし、あなたが今回予測するデータにそこまで詳しくない場合は、普段そのデータを触っている人にしっかりヒアリングしたうえでデータの集計・加工をすることをお勧めします。
集計するデータは条件をそろえる事を意識する
集計するデータについては条件を揃えることを意識してください。学習データの抽出の条件がバラバラだと作成される予測モデルは誤ったものになる可能性があります。
例えば、今回の事例の場合だと休眠予測をするためにユーザーの「課金回数」や「課金金額」という説明変数を選択しています。
しかし、この説明変数はユーザーの登録時期によってバラバラになります。「1日前に登録したユーザー」と「一週間前に登録したユーザー」だと差が出るのは当然です。
なので今回の事例では「登録してから一週間での課金回数・課金金額」としています。こうすることでユーザー間の条件をそろえることが出来ます。
CDPで機械学習を実行する
データの集計・加工が出来たらいよいよ機械学習を実行します。
TreasuredataのHivemallという機械学習専用のライブラリを使うことで予測モデルの作成をすることが出来るのですが、細かい手順については今回省略します。気になる方はこちらをご覧ください。
Hivemallで機械学習ができるメリットは何といっても、SQLだけで実装できる点です。Python等のプログラミング言語が書けなくても、普段SQLでデータ集計をしてる方なら問題なく実装が可能でしょう。
また、TreasureData内でデータ集計~機械学習の実装~ソリューションとの連携まで一気通貫で実行できる点も大きなメリットとなります。
予測モデルの精度を評価する
さて、予測モデルが完成したら、いよいよその精度を評価します。
この評価方法としてAUCなどで評価することが一般的で、こちらの評価方法もSQLで実装することが可能です。(具体的な手順はこちらをご参考ください)
しかし、機械学習の予測モデルをつかって施策を行う場合、ビジネスサイドの方々にAUCの説明をするのは中々難しいケースが多いです。「aucの値が0.8より大きいのでかなり精度の高い予測モデルです」と言われてもきっとピンとこないでしょう。
そういった際に、混同行列を用いて精度について説明するのがおすすめです。
混同行列について
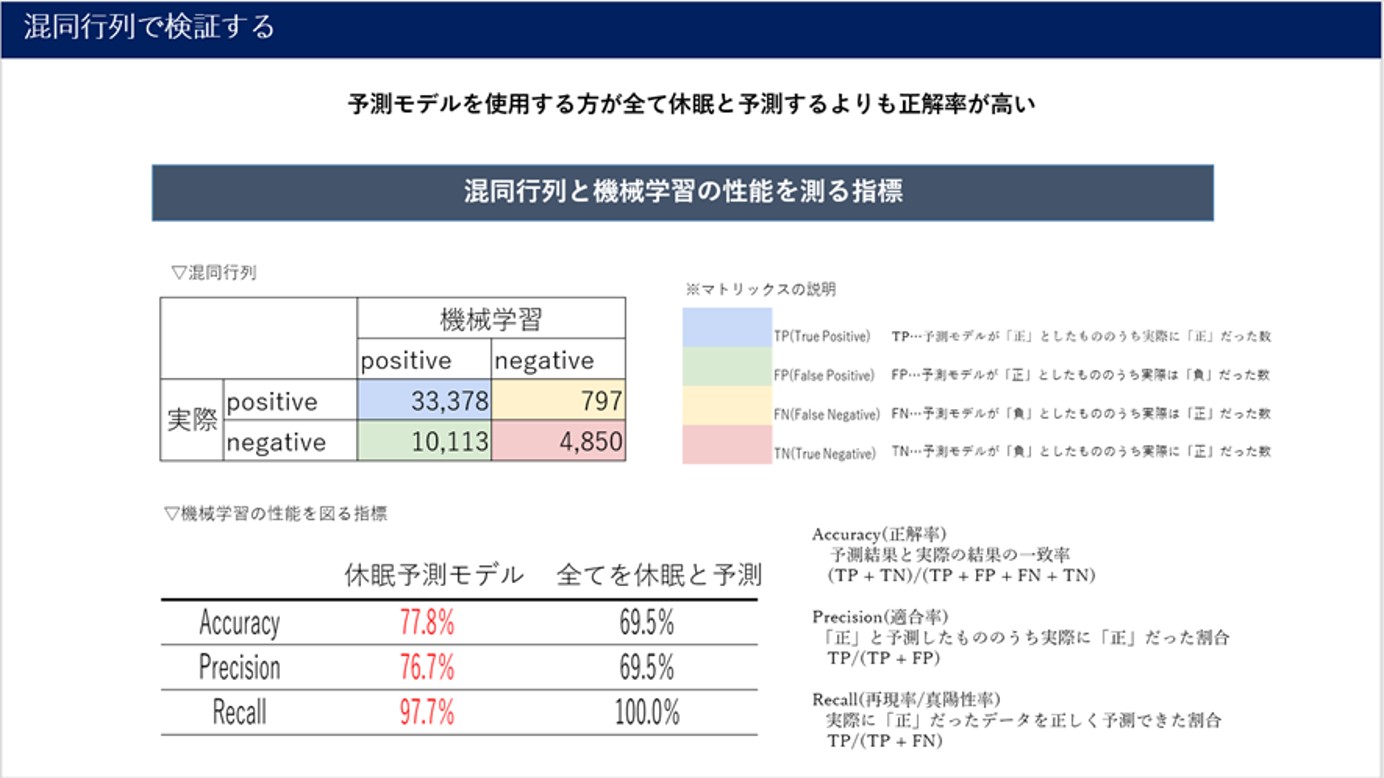
混同行列とは、機械学習でデータを分類した際に、その結果が正解してるのか・不正解なのかをマトリックスで表現した評価方法となります。予測モデルにより予測された結果がどのくらいあっていたのか、または間違っていたのかを測るので非常に明快な評価指標となります。
TP…予測モデルが「正」としたもののうち実際に「正」だった数
FP…予測モデルが「正」としたもののうち実際は「負」だった数
FN…予測モデルが「負」としたもののうち実際は「正」だった数
TN…予測モデルが「負」としたもののうち実際に「正」だった数
また、上記の4象限の結果から以下の方法で検証します。
Accuracy(正解率)…予測結果と実際の結果の一致率
(TP + TN)/(TP + FP + FN + TN)
また、ターゲットのクラスに偏りがあるデータ(不均衡データ)の場合は以下のPrecisionやRecallなどの方法で検証する場合もあります。
Precision(適合率)…「正」と予測したもののうち実際に「正」だった割合
TP/(TP + FP)
Recall(再現率/真陽性率)…実際に「正」だったデータを正しく予測できた割合
TP/(TP + FN)
以上のように、予測モデルで予測されたものがどれくらい正解しているか・不正解なのかを示すことで普段からデータサイエンスに触れていないビジネスサイドの方々にも精度を説明しやすくなるでしょう。
今回の事例のケースだと正解率は77.8%とランダムで予測する場合(50%)場合やすべてを正とする場合(69.5%)よりも高いことから、まずまずの精度であることがわかります。
閾値について
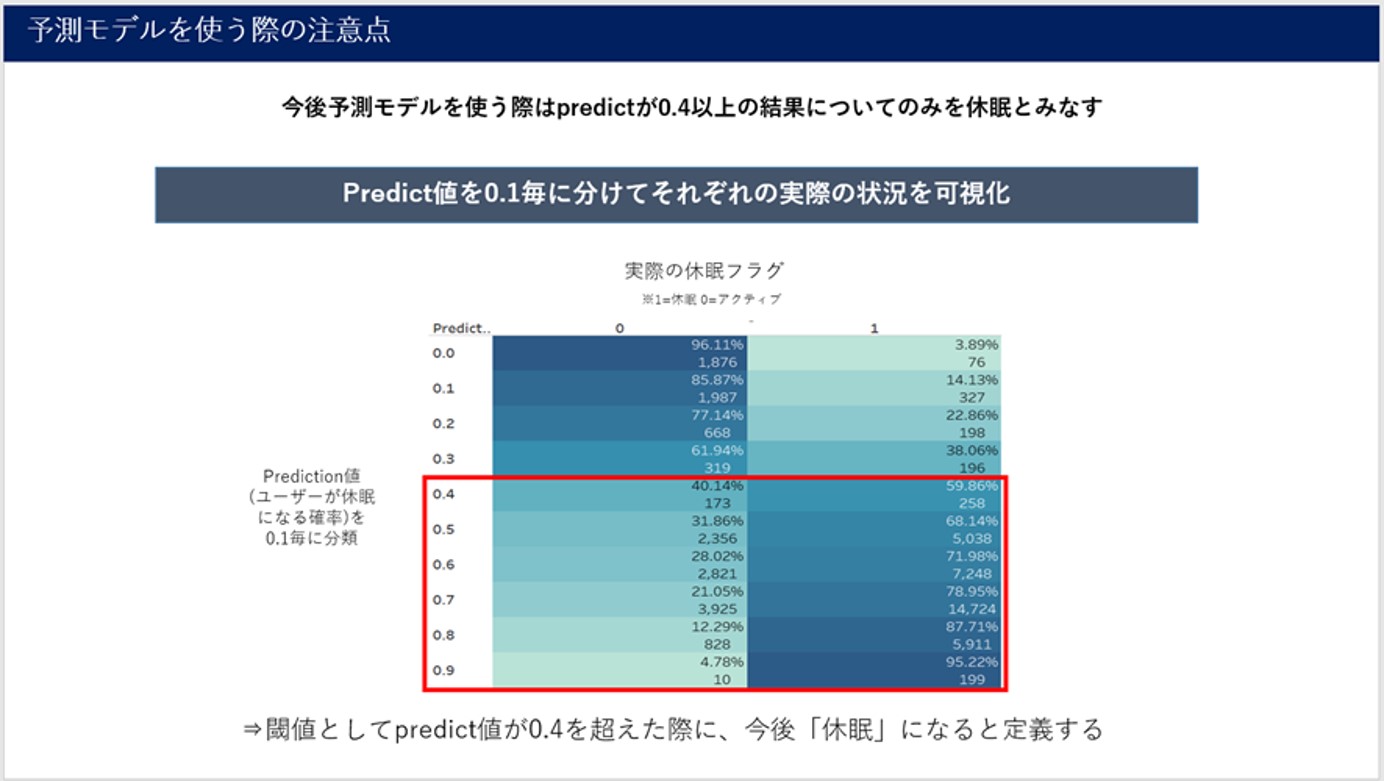
また、上記で混同行列を行う際に予測結果が「正」・「負」のどちらか、という表現を用いましたが予測モデルの結果として「正」・「負」が出てくるわけなく、あくまで予測スコアが出てきます。
なので、予測スコアが「正」・「負」どちらに当たるのか、スコアの閾値を求める必要あります。
今回の事例のケースでは、過去実績を参考に可視化をし、スコアが0.4以上であれば「正(休眠)」それ以下であれば「負(アクティブ)」というように閾値を設定しています。
まとめ
いかがだったでしょうか?今回は事例の内容から機械学習をする際のコツや考え方の例をご紹介いたしました。これからCDPを導入される方や是非ご検討してみてください。
また、まだCDPを導入する予定はないが現状のデータで手軽に機械学習をしてみたい方に向けて弊社ではvizという機械学習のツールも用意しております。こちらも是非ご検討下さい。
関連資料
》CDP総合支援サービス ~構想・構築・活用~ のサービス資料はこちら
》vizサービスサイトはこちら
》詳細資料・お問い合わせはこちら
本件に関するお問い合わせは下記にて承ります。
株式会社DataCurrent
info@datacurrent.co.jp