2021.06.11 コラム
【テックコラム】Vertex AI と AutoML で画像分類する
● はじめに
こんにちは、DataCurrentの笹沼です。
Google Cloud から Vertex AI が発表されました。
弊社でも MLOps として、Kubeflow や AI Platform を活用していますが、さらに使いやすくなったと聞いて 、今回は Vertex AI で画像分類をしてみます。
● 目次
● Vertex AIについて
Vertex AI は、各種 ML ツールを統合したプラットフォームです。
統合された UI および API のもとで、機械学習のプロセス全体を効率的に行えることが特徴です。
機械学習のソリューションを適材適所で使い分けていくのもいいのですが、連携に時間やスキルが必要です。
機械学習で解決したい本質的な課題解決の時間が削られてしまわないように、このような統合されたプラットフォームを利用します。
以下は、 Google Cloud からの引用です。
Vertex AI は、統一された API、クライアント ライブラリ、ユーザー インターフェースに AutoML と AI Platform を統合します。Vertex AI を使用すると、AutoML トレーニングとカスタム トレーニングの両方を利用できます。トレーニングにどちらの方法を選択しても、Vertex AI を使用して、モデルの保存、モデルのデプロイ、予測のリクエストを行えます。
Vertex AI のドキュメントより引用
現在、データ サイエンティストは別々の機械学習の部分的なソリューションを手動で組み合わせることを余儀なくされています。その結果、モデルの開発やテストの段階で時間的な遅れが生じ、実際に本番環境の運用にこぎつけるモデルはごくわずかに限られているのが現状です。このような問題に対処するため、Vertex AI は複数の Google Cloud サービスをまとめ、統合された UI および API のもとで ML を構築できるようにしているのが特長です。機械学習モデルの構築、トレーニング、デプロイのプロセス全体を効率的に大規模なスケールで行えるようにしています。この統合環境のもとでは、ML モデルをテストから本番環境に迅速に移行できるのに加えて、パターンや異常の効率的な検出や、予測や判断の的確性向上といった効果も得られ、全体として、変化の激しい市場にアジャイルに対応することが可能になります。
Google Cloud Blogより引用
● 使用するデータ
本コラムで使用するのは Oxford-IIIT Pet Dataset というデータセットです。
このデータセットは、犬25種と猫12種の合計37種の写真から構成されています。
犬や猫よりも細かい犬種や猫種を分類するためのデータセットです。CC BY-SA 4.0 のもと配布されています。
データセットの中身を見てみます。
以下の表は、データセットに含まれている画像の枚数をカテゴリ毎に集計したものです。
犬種や猫種を合わせて7349枚、各カテゴリに概ね200枚の画像が用意されています。
実際の画像は以下のようになっています。
多種多様な画像データになっていることがわかるかと思います。
Vertex AI を利用する前にデータの下準備を簡単にします。
Oxford-IIIT Pet Dataset を解凍し Google Cloud Storage に画像をアップロードします。
アップロードした画像とラベルの一覧をGoogle Cloud Storage にアップロードします。
以下はそのCSVファイルの内容です。1列目が Google Cloud Storage 上にアップロードした画像、2列目がラベルになっています。
この形式にしておくと Vertex AI にインポートする際にラベルありの画像データとなります。
実際にはラベル付けの工程があるのですが、今回は便宜的にファイル名の一部をラベルとしています。
$ head images.csv gs://<BUCKET_NAME>/images/boxer_16.jpg, boxer gs://<BUCKET_NAME>/images/chihuahua_165.jpg, chihuahua gs://<BUCKET_NAME>/images/pug_183.jpg, pug gs://<BUCKET_NAME>/images/english_setter_1.jpg, english_setter gs://<BUCKET_NAME>/images/chihuahua_170.jpg, chihuahua gs://<BUCKET_NAME>/images/english_cocker_spaniel_17.jpg, english_cocker_spaniel gs://<BUCKET_NAME>/images/samoyed_39.jpg, samoyed gs://<BUCKET_NAME>/images/Egyptian_Mau_62.jpg, Egyptian_Mau gs://<BUCKET_NAME>/images/samoyed_36.jpg, samoyed gs://<BUCKET_NAME>/images/german_shorthaired_3.jpg, german_shorthaired
● Vertex AI
では、利用するサービスとデータの整理ができたので、さっそく Vertex AI を操作してみます。
【データセット作成】
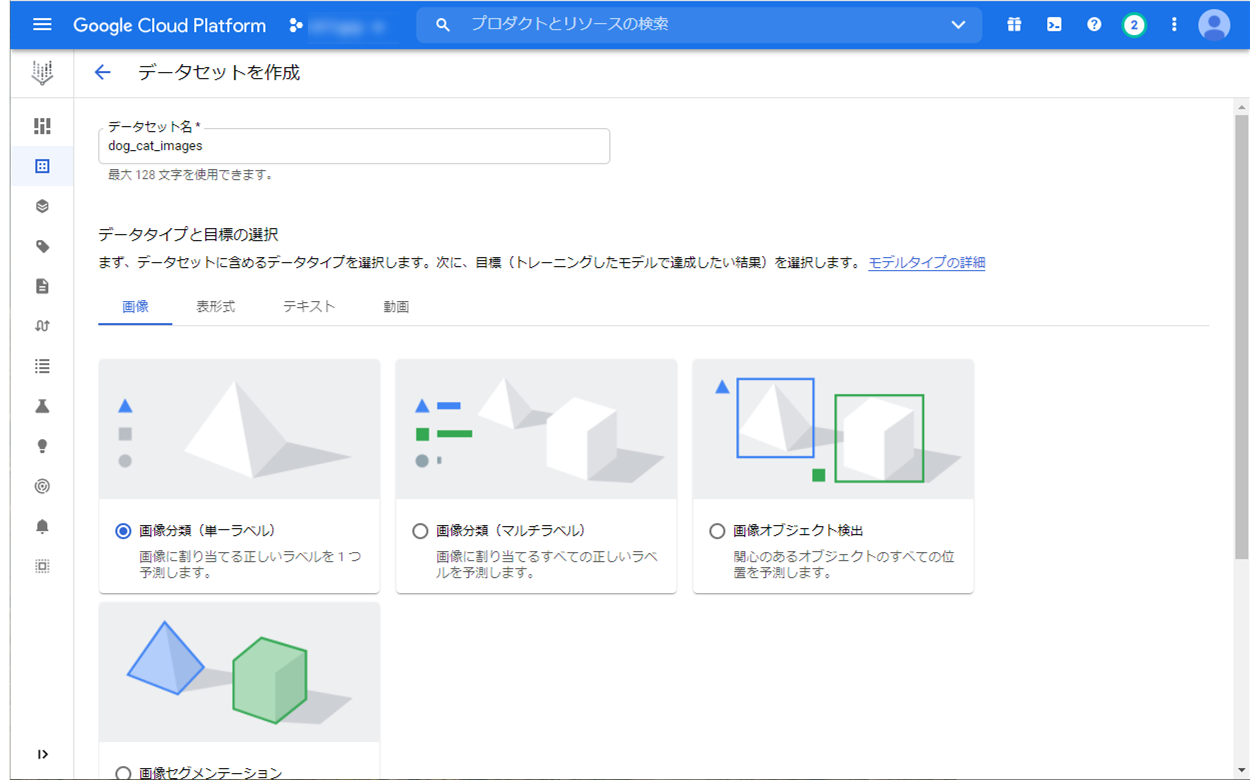
まず、Vertex AI 上にデータセットを作成します。
データセット名は “dog_cat_images” にしています。
「データタイプと目標の選択」は画像分類(単一ラベル)を選択します。
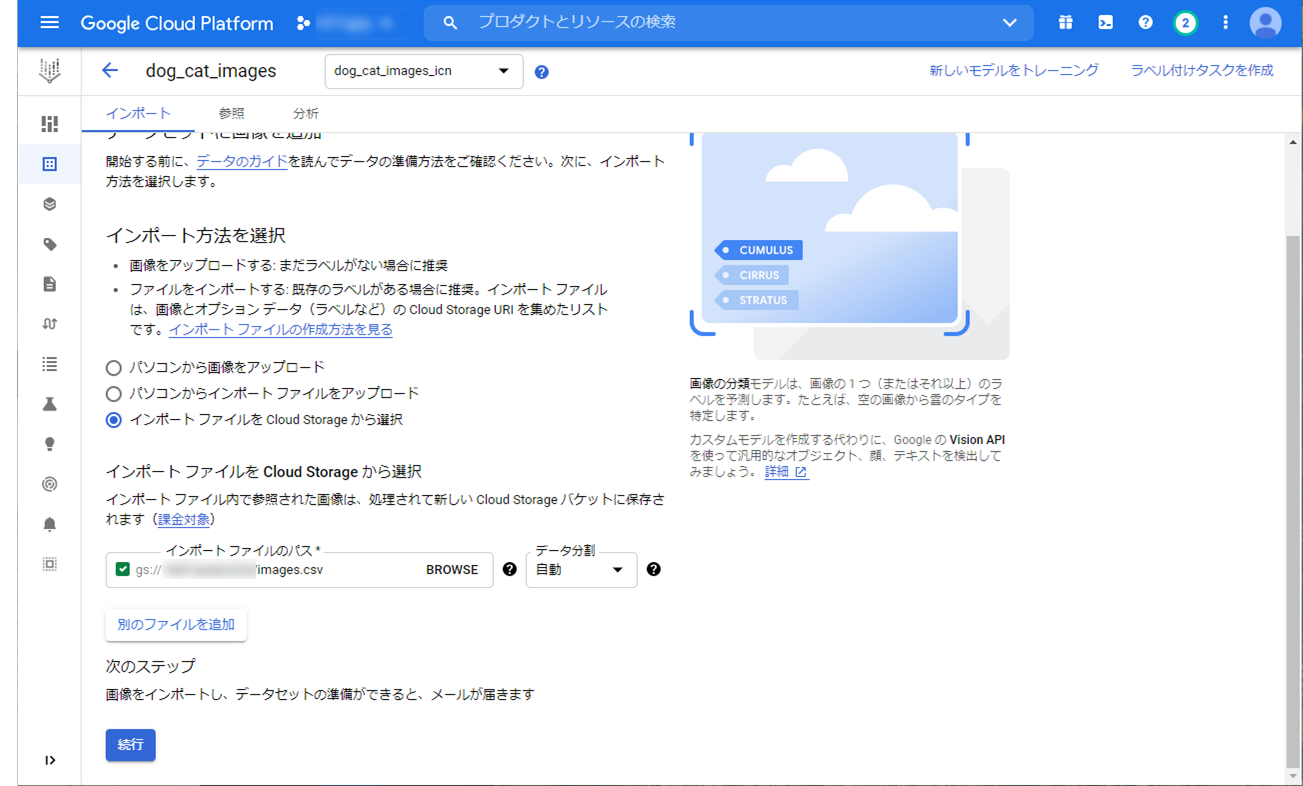
次に、作成されたデータセットに画像をインポートします。
画像は事前にすべて Google Cloud Storage へアップロードしていますので、「インポートファイルを Cloud Storage から選択」を選択し、「インポート ファイルのパス」に作成しておいた ”gs://<BUCKET_NAME>/images.csv” ファイルを指定します。
しばらくするとインポートが完了します。
中央に画像、左に各種ラベルがあります。犬種や猫種ごとにおおむね200枚の画像がラベリングされているのがわかります。
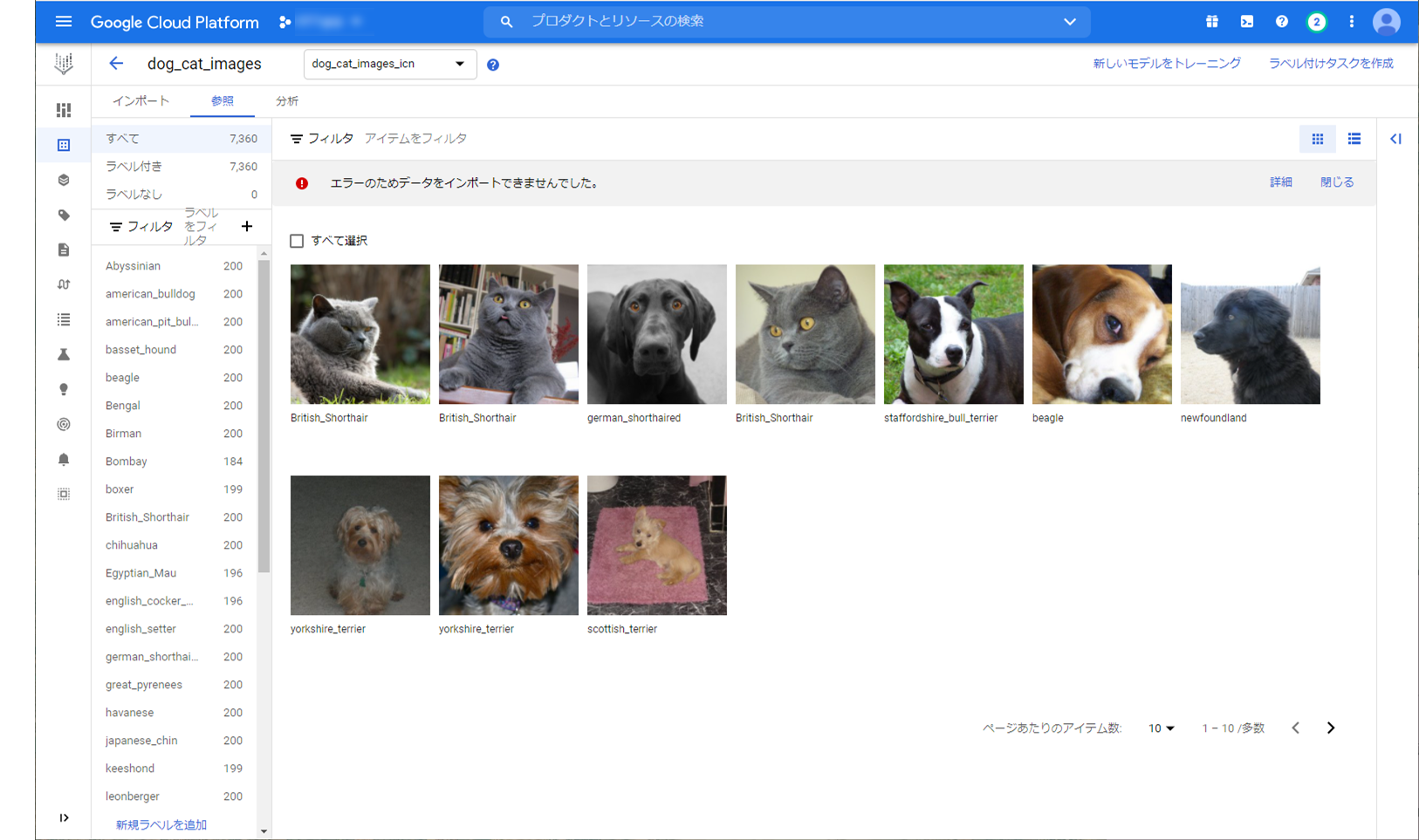
上部にエラーが表示されていますが、同じ画像があったようです。重複する画像はインポートしないようですね。
Warning: Annotation `Egyptian_Mau` is deduped. for: gs://<BUCKET_NAME>/images.csv line 6548,gs://<BUCKET_NAME>/images.csv line 433 Warning: Annotation `Bombay` is deduped. for: gs://<BUCKET_NAME>/images.csv line 503,gs://<BUCKET_NAME>/images.csv line 2635 ...
【トレーニング】
トレーニングを行います。
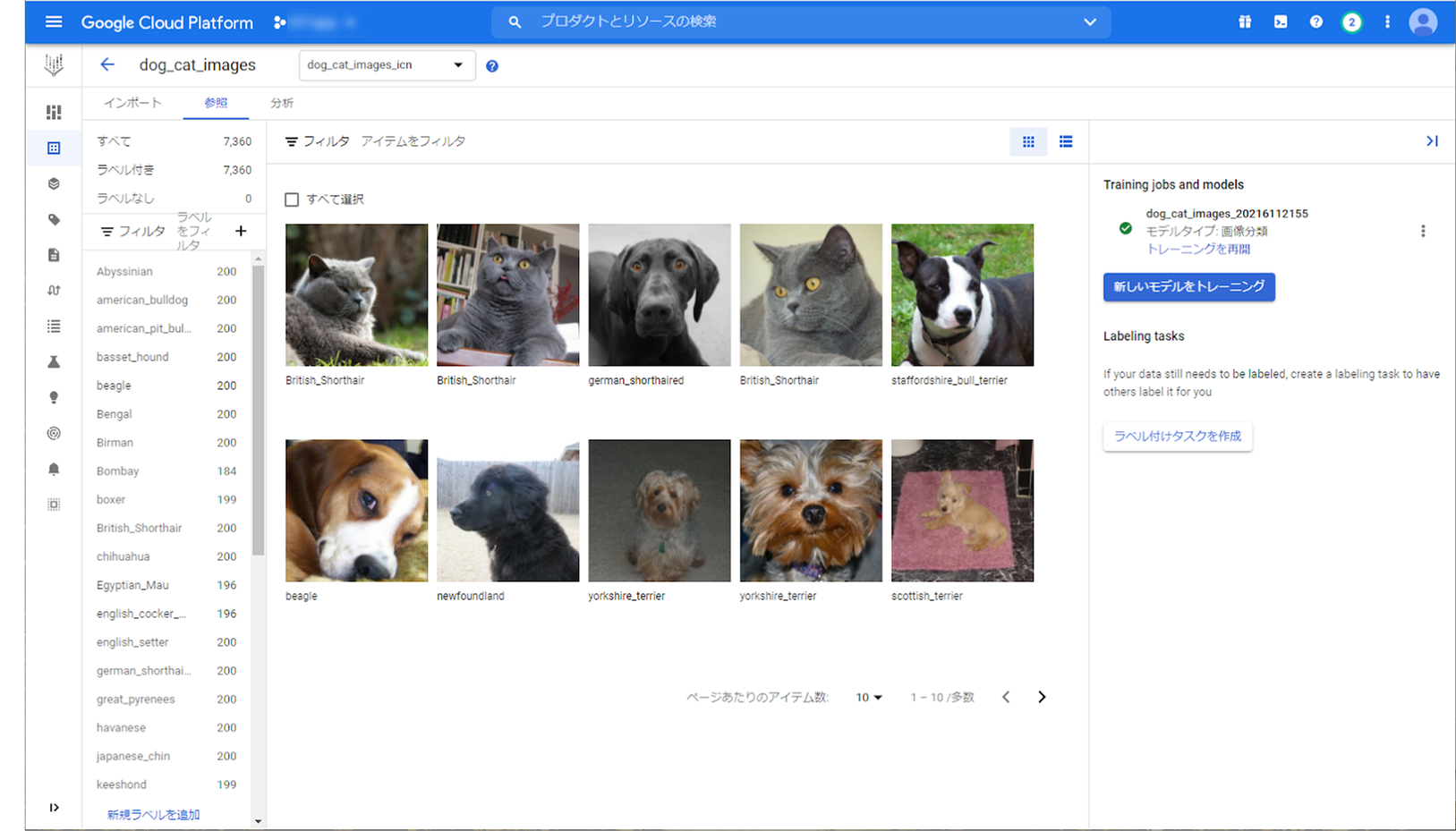
データセットのインポート後、表示される右のパネルから「新しいモデルをトレーニング」を押下します。
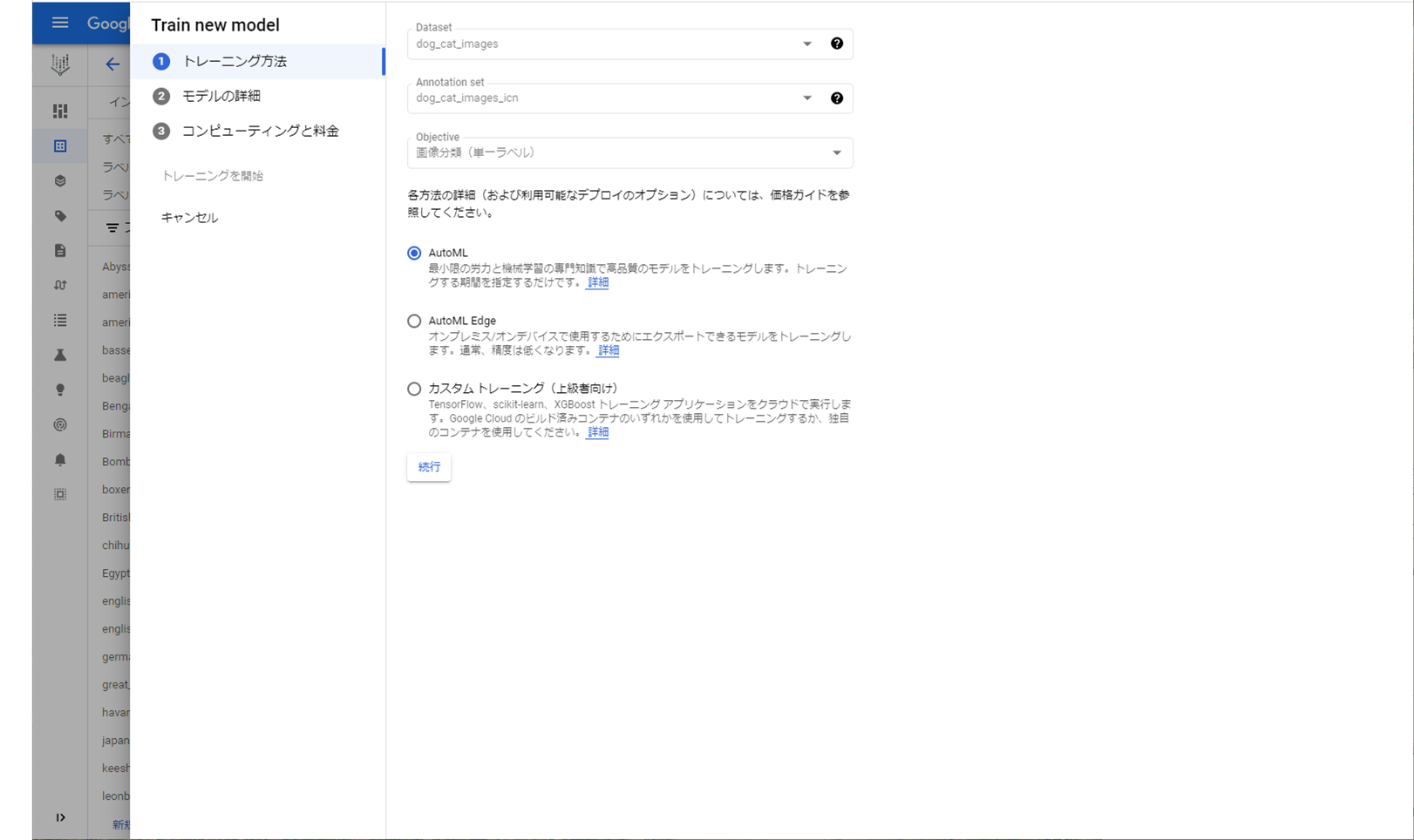
「トレーニング方法」は、今回は “AutoML” を選択しています。
ここで Vertex AI から Auto ML を利用できるようです。
「モデルの詳細」では、Model name を “dog_cat_images_日付” にしました。
「コンピューティングと料金」では、Budget を “8” にしました。
もっと少なくても大丈夫そうですが、最低ノード数が “8” からのためです。
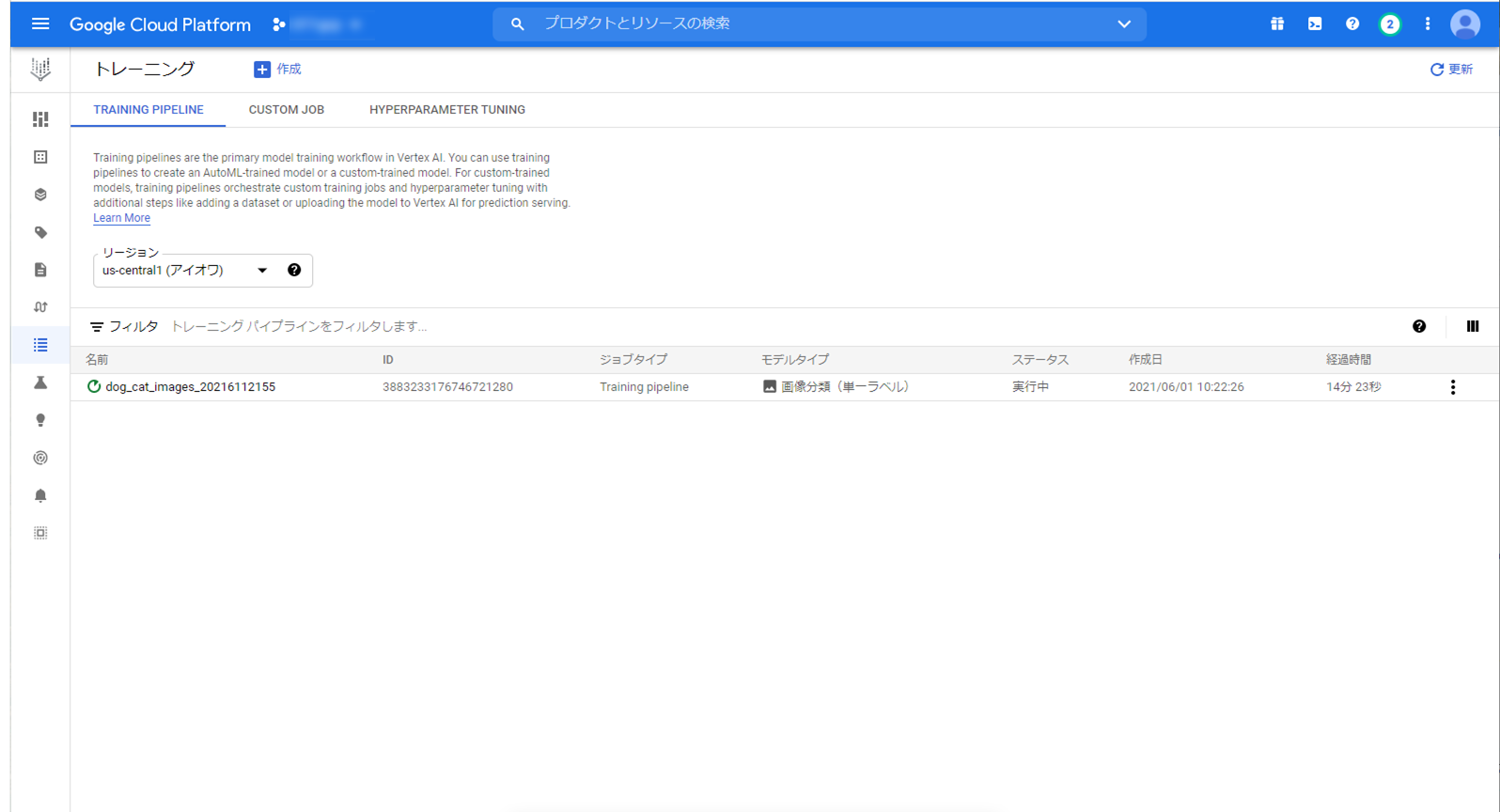
トレーニング中の画面です。大体20分ほどで完了しました。
完了後、モデルの詳細が見れるのですが、アルゴリズムはAutoMLと表示されています。
AutoMLは初めて使ったのですが、どういう手法とかは全く見せないんですね。
【モデルのデプロイ】
モデルをデプロイします。
「コンピューティング ノードの数」は “1” にしています。
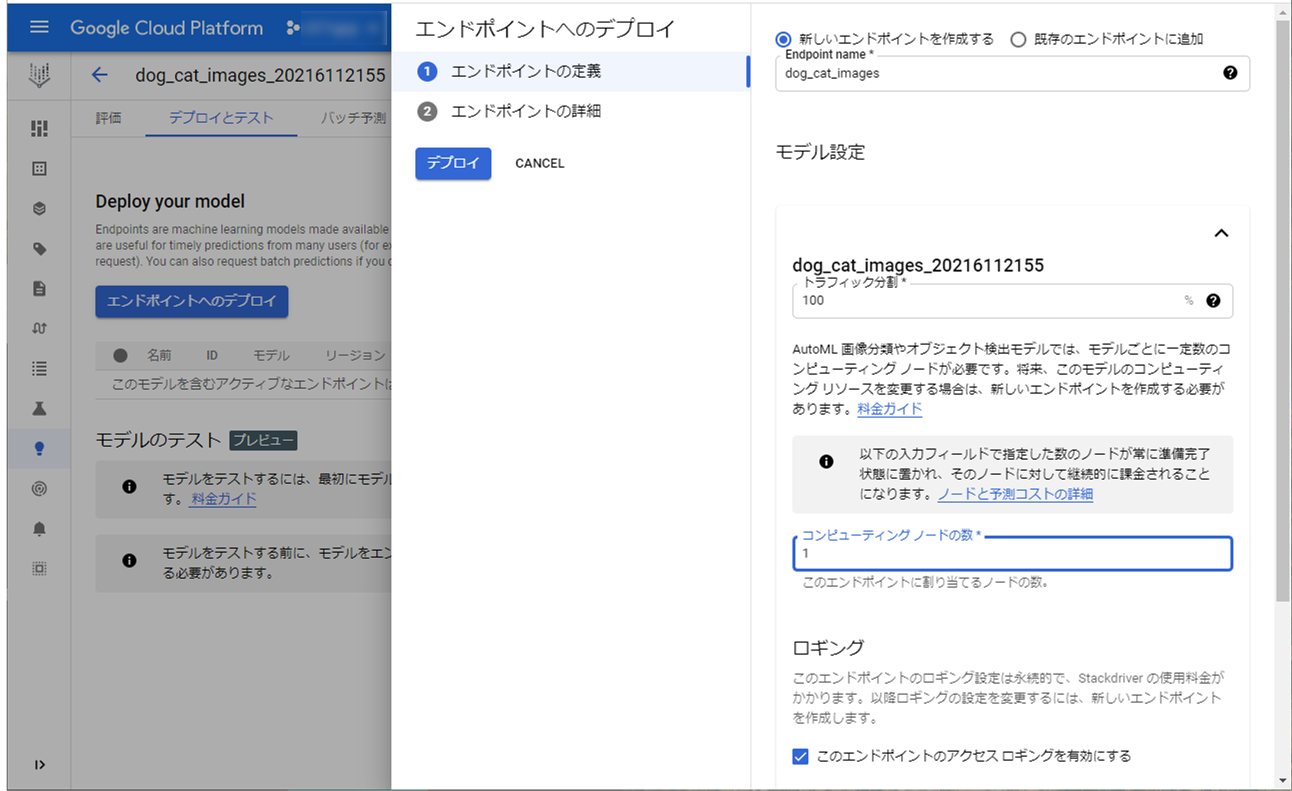
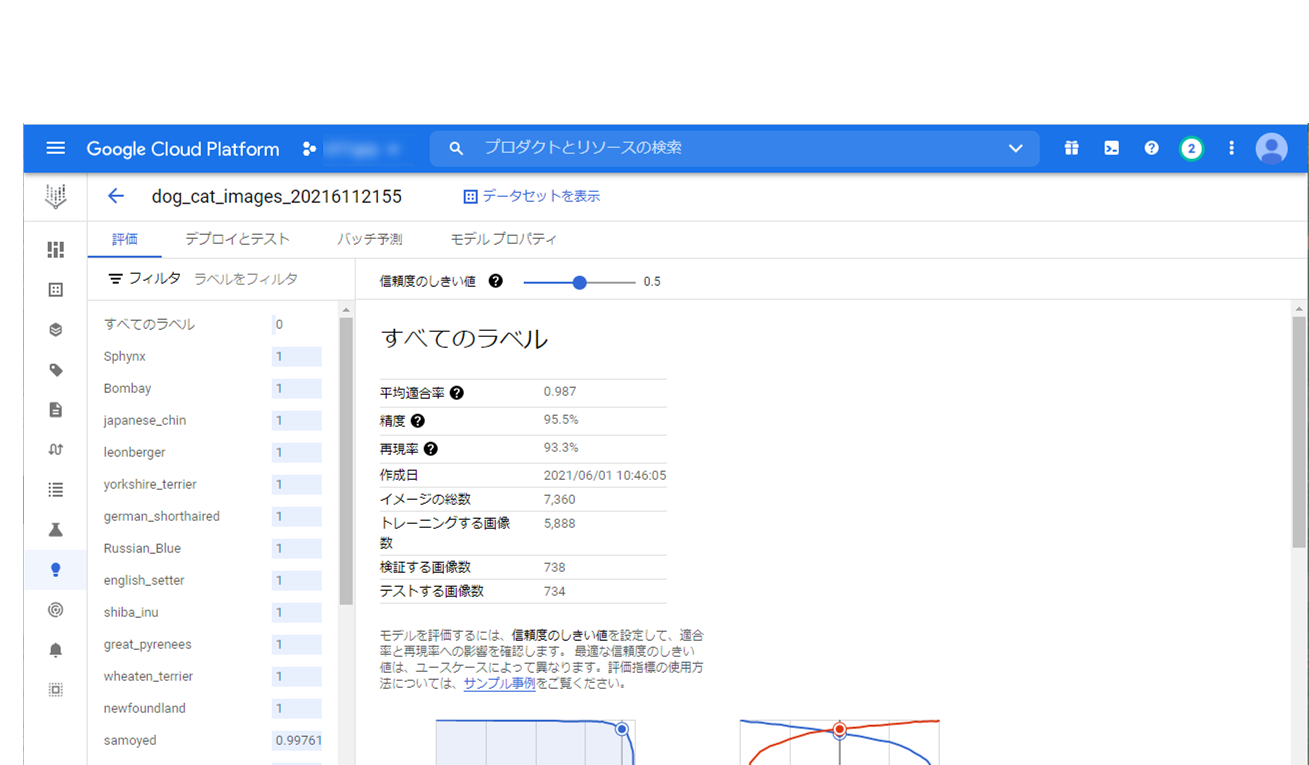
デプロイが完了しましたら、評価を見てみます。
とても良い評価でした。
値の説明は割愛しますが、平均適合率は高いほど高品質のモデルであることを示します。
作成したモデルは “0.987” なので品質の高いモデルになりました。
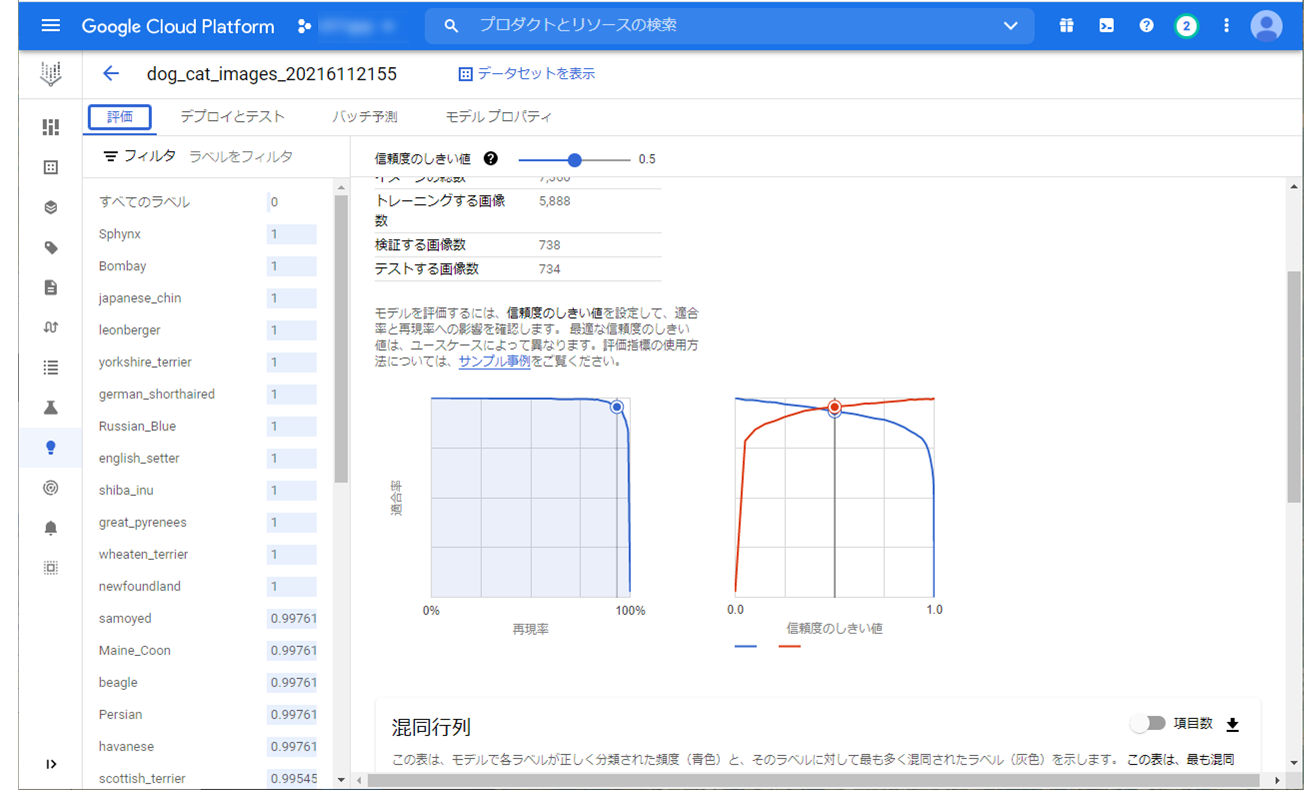
評価画面上で信頼度のしきい値を操作できるのがいいですね。
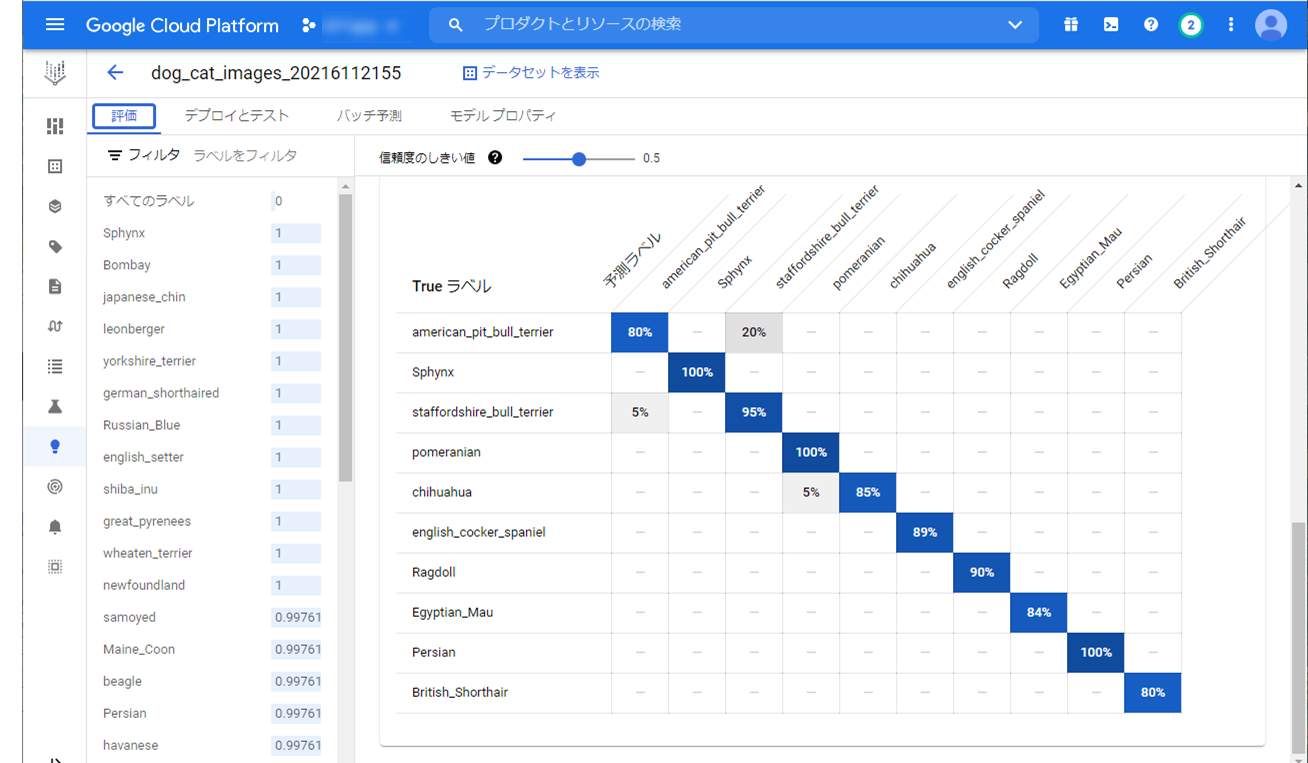
予測
では、実際に予測をしてみます。
画像は、犬の画像、猫の画像を使用します。
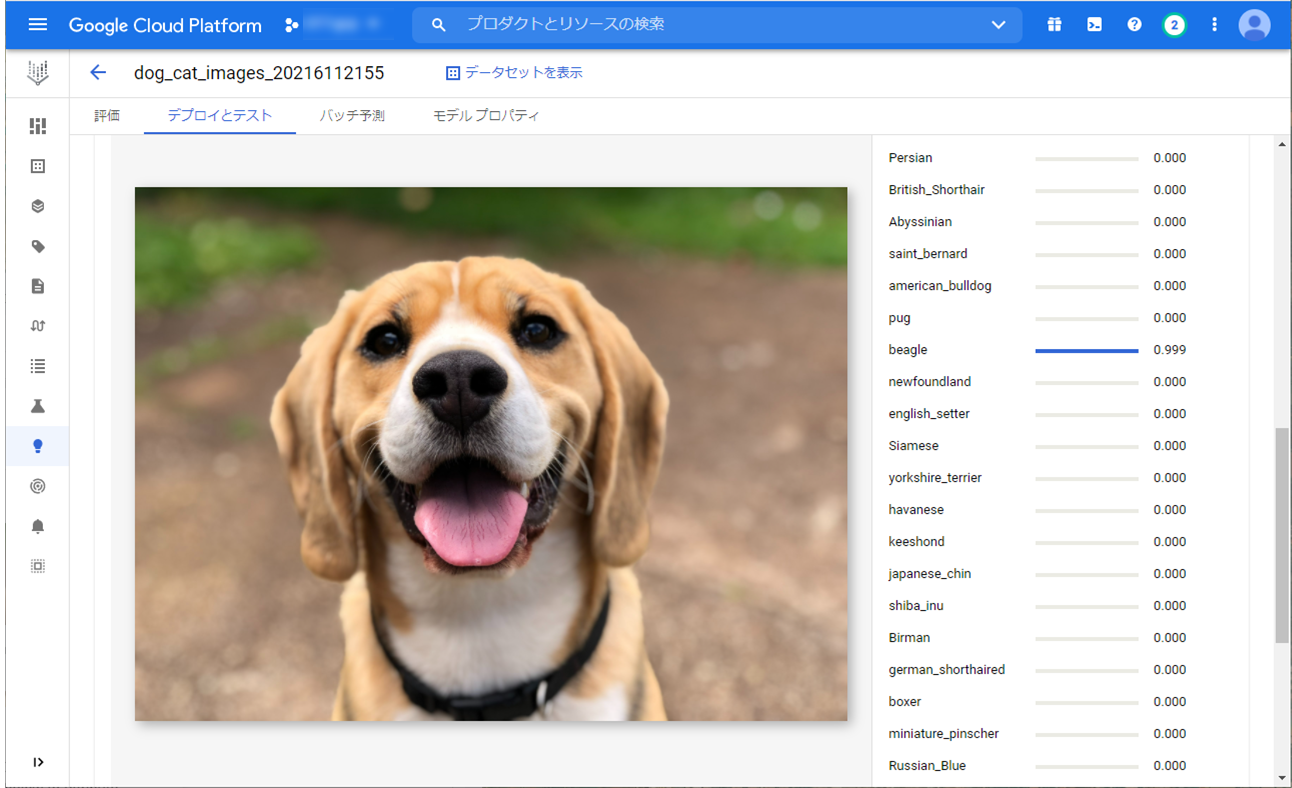
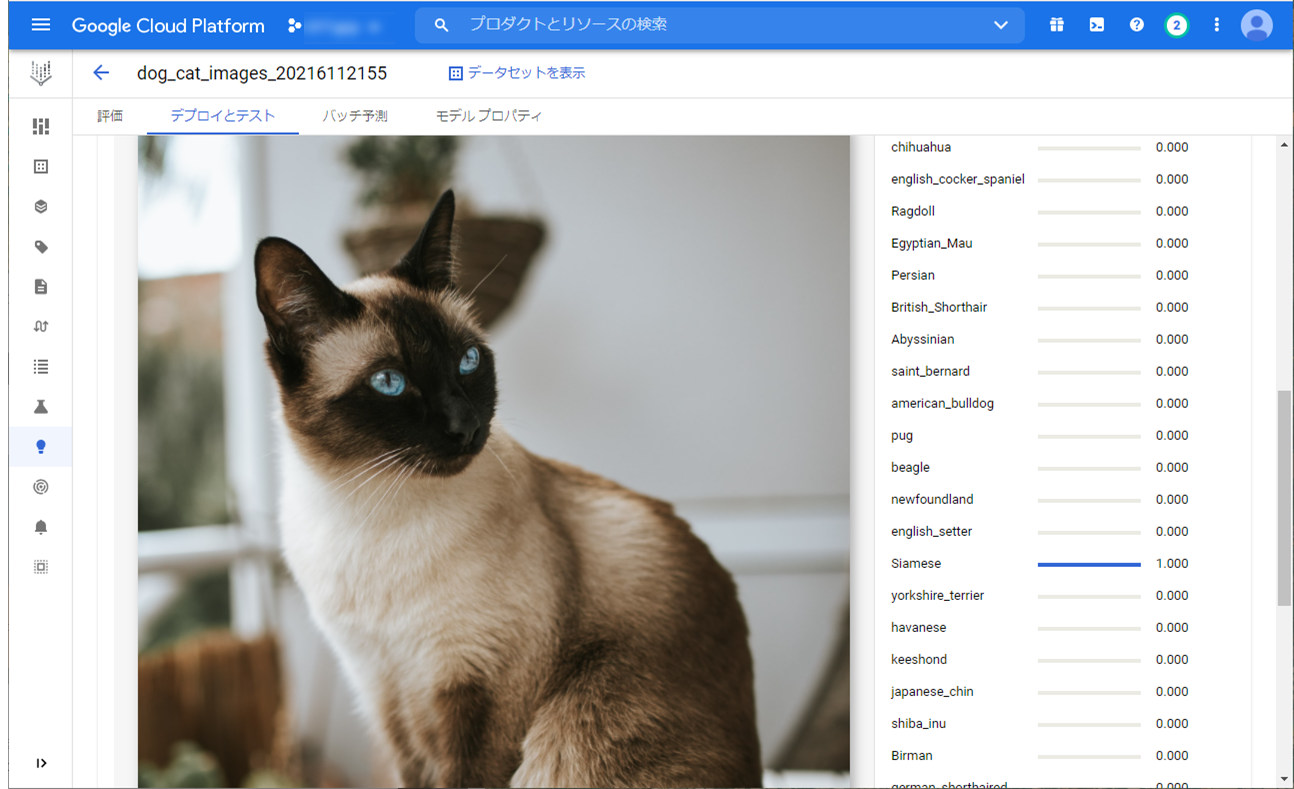
犬の画像は、”beagle” 、猫の画像は、”Siamese” と予測してくれていました。
ちゃんと犬種と猫種を分類しています。
デプロイ後の画面で画像をアップロードするとテストができるので、簡単に検証できて便利でした。
せっかくエンドポイントを作成したので、APIでリクエストもしてみます。
「confidences」”0.999730051″で、”Siamese” と予測しています。うまくいっていますね。
$ curl \
> -X POST \
> -H "Authorization: Bearer $(gcloud auth print-access-token)" \
> -H "Content-Type: application/json" \
> https://us-central1-aiplatform.googleapis.com/v1alpha1/projects/${PROJECT_ID}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict \
> -d "@${INPUT_DATA_FILE}"
{
"predictions": [
{
"displayNames": [
"Siamese"
],
"ids": [
"4515163191159816192"
],
"confidences": [
0.999730051
]
}
],
"deployedModelId": "6887252875458641920"
}
● おわりに
犬種と猫種の画像分類をすることができました。
AutoMLを使ったNoCodeでの機械学習やそのML ワークフローの構築を専門知識なしでできるので、機械学習での取り組みをよりいっそう促進されると思います。
AutoMLのおかげでデータサイエンティストがいなくとも機械学習ができるようになってきています。
しかし、実データはここまできれいに識別できない場合もあります。
また、今回は省略しましたが、実運用になってくるとデータ基盤の構築や機械学習のパイプラインなど考慮することがたくさん出てくるかと思います。
そういうことよくわからないけど機械学習に取り組んでみたいなどありましたら、お気軽にご相談ください。
本件に関するお問い合わせは下記にて承ります。
株式会社DataCurrent
info@datacurrent.co.jp