2025.04.07 コラム
Gemini のバッチ予測を試してみた
DataCurrent の金子です。Gemini のバッチ予測機能を試してみました。
バッチ予測機能を使うと、以下のメリットがあります。
- 大量のデータに対して Gemini を適用することができます。
- 標準リクエストより 50% 割引されます。
※ この記事は、2025 年 3 月時点の Google Cloud の公式ドキュメント Batch prediction を参考にしています。記事の内容は古くなっている可能性がありますので、最新の情報は公式ドキュメントをご確認ください。
Gemini のバッチ予測とは
通常の Gemini API を使って大量のデータを処理しようとすると、リクエスト数の割り当て容量が不足し、エラーコード 429 が返されることがあります。
また、BigQuery の ML.GENERATE_TEXT 関数を使う場合も同様で、resource exhausted エラーが返されることがあるようです。
このような場合に、リクエスト容量を気にせずに大規模データセットに対して効率的に Gemini を適用するには、バッチ予測機能がおすすめです。
サポートするモデル
- Gemini 2.0 Flash
- Gemini 2.0 Flash-Lite
その他、Gemini 1.5 などの従来モデルもサポートされていますが、モデルのライフサイクルに十分注意してください。
バッチ予測の料金
バッチ予測は、標準リクエストより 50% 割引されます。詳細は料金ページをご確認ください。
バッチ予測の注意事項
バッチ予測は、オフピークの容量が優先されるため、処理に時間がかかることがあります。処理時間は保証されません。データ処理をフロー化させる際は、データの鮮度に十分注意してください。
バッチ予測を試してみた
ここでは、BBC ニュースの公開データセット(BigQuery の bigquery-public-data.bbc_news でホストされています)を使って、ニュースの本文を技術、ビジネス、政治、スポーツ、エンターテインメントという 5 つのカテゴリに分類してみます。
データについては、事前にテーブルから body と category カラムのみ 10 件のデータを取得し、ローカルに bbc_news-fulltext.csv として保存しました。
body カラムは Gemini への入力として使い、category カラムは出力結果を比較する参考データとして利用します。
bbc_news-fulltext.csvのイメージ
| body | category |
|---|---|
| England forward Martin Corry… | sport |
| We have not performed but… | sport |
1. Gemini への入力内容を準備してアップロードします。
バッチ予測は、Cloud Storage にアップロードする方法と、BigQuery にアップロードする方法の 2 つがあります。
今回は、Cloud Storage にアップロードする場合を例に説明します。
Cloud Storage には Gemini の JSON リクエストを JSONL 形式でアップロードします。
Gemini の JSON リクエストは公式ドキュメントの API Reference や、Vertex AI の Reference ページを参考にするとよいでしょう。
今回は、Cloud Storage に gemini-batch-20250318/bbc_news-fulltext.jsonl というオブジェクトパスでアップロードしました。
import os
import csv
import json
import tempfile
from google.cloud import storage
# 事前に環境変数 BUCKET に値をセットします。
BUCKET = os.environ["BUCKET"]
CATEGORIES = [
"sport",
"entertainment",
"tech",
"business",
"politics",
]
SYSTEM = f"""
ユーザーが与えるテキストを以下のカテゴリに分類せよ。
{CATEGORIES}
回答はカテゴリのみ単語で返すこと。
"""
def format_json(
index: str,
system_instruction: str,
user_prompt: str,
) -> str:
req = {
"contents": [{
"role": "user",
"parts": [{
"text": user_prompt
}]
}],
"systemInstruction": {
"parts": [{
"text": system_instruction
}]
},
"generationConfig": {
"temperature": 0,
"seed": 0,
"responseMimeType": "application/json",
"responseSchema": {
"type": "string",
"enum": CATEGORIES
},
},
"labels": {
# 後で分類結果を正解と比較できるように index を id として設定した。
# 検証時は数字を文字列にしただけではうまく処理できなかったので、プレフィックスに n を付与した。
"id": f"n{index}"
}
}
return json.dumps({"request": req}, ensure_ascii=False)
bucket = storage.Client().bucket(BUCKET)
blob = bucket.blob("gemini-batch-20250318/bbc_news-fulltext.jsonl")
# jsonl ファイルを作成
with tempfile.NamedTemporaryFile(mode="w") as w:
with open("bbc_news-fulltext.csv", "r", encoding="utf-8") as r:
reader = csv.reader(r)
next(reader)
i = 0
for i, row in enumerate(reader):
body = row[0]
request = format_json(str(i),
system_instruction=SYSTEM,
user_prompt=body)
w.write(request + "\n")
w.flush()
blob.upload_from_filename(w.name)
2. バッチ予測を実行します。
2025 年 3 月時点では、バッチ予測はコンソール上から実行することはできないようです。
Python を利用できる場合は、Google Gen AI SDK を使ってバッチ予測を実行するとよいでしょう。
今回は、公式ドキュメントのコードとほぼ同じですが、output_uri に gs://{BUCKET}/gemini-batch-20250318/output/ を指定して実行しました。
import time
from google import genai
from google.genai.types import CreateBatchJobConfig, JobState, HttpOptions
# 事前に以下の環境変数を設定する必要があります。
# GOOGLE_CLOUD_PROJECT: GCP プロジェクト ID
# GOOGLE_CLOUD_LOCATION: GCP リージョン
# GOOGLE_GENAI_USE_VERTEXAI: True
client = genai.Client(http_options=HttpOptions(api_version="v1"))
job = client.batches.create(
model="gemini-2.0-flash-001",
src=f"gs://{BUCKET}/gemini-batch-20250318/bbc_news-fulltext.jsonl",
config=CreateBatchJobConfig(
dest=f"gs://{BUCKET}/gemini-batch-20250318/output/"),
)
print(f"Job name: {job.name}")
# Job name: projects/467677818012/locations/us-central1/batchPredictionJobs/484549293982613504
print(f"Job state: {job.state}")
# Job state: JobState.JOB_STATE_PENDING
completed_states = {
JobState.JOB_STATE_SUCCEEDED,
JobState.JOB_STATE_FAILED,
JobState.JOB_STATE_CANCELLED,
JobState.JOB_STATE_PAUSED,
}
while job.state not in completed_states:
time.sleep(30)
job = client.batches.get(name=job.name)
print(f"Job state: {job.state}")
# Job state: JobState.JOB_STATE_RUNNING
3. バッチ予測の結果を確認します。
3 分ほど待つとバッチ予測が完了しました。
バッチ予測の結果は Cloud Storage に出力が保存されます。
今回の場合、gs://{BUCKET}/gemini-batch-20250318/output/ 配下に新たに prediction-model-2025-03-19T09:34:27.764709Z というディレクトリが作成され、その中に predictions.jsonl ファイルが保存されていました。
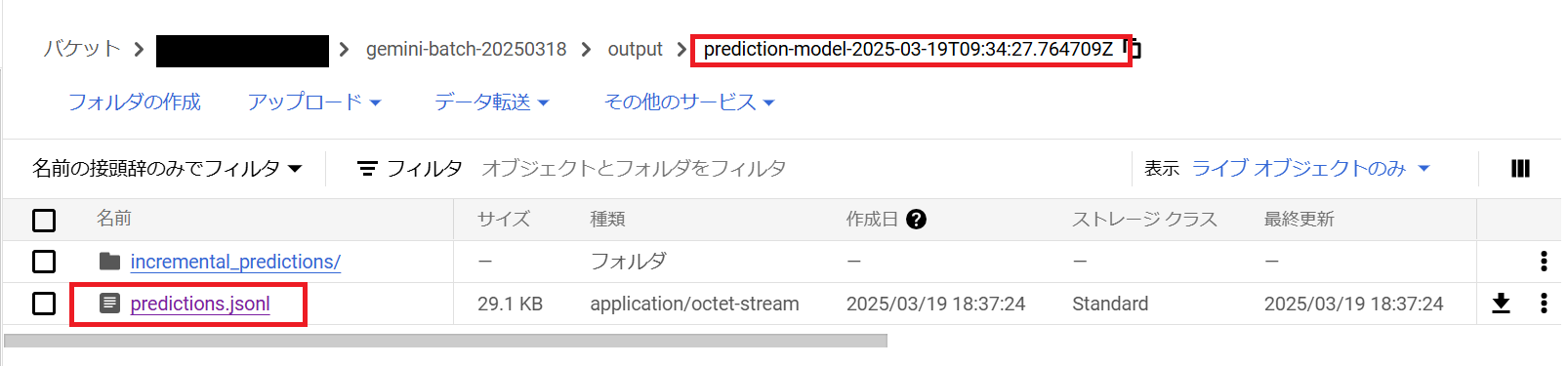
このファイルには、バッチ予測の結果が JSONL 形式で保存されています。
ファイルの中身の最初の 2 行は以下のようになっていました。リクエスト時に labels を指定して、インデックスをメモしましたが、結果を見てみると順番通りに保存されている訳ではないようです。
{"status":"","processed_time":"2025-03-19T09:36:26.583+00:00","request":{"contents":[{"parts":[{"text":"The US【省略】basis.\n"}],"role":"user"}],"generationConfig":{"responseMimeType":"application/json","responseSchema":{"enum":["sport","entertainment","tech","business","politics"],"type":"string"},"seed":0,"temperature":0},"labels":{"id":"n7"},"systemInstruction":{"parts":[{"text":"\nユーザーが与えるテキストを以下のカテゴリに分類せよ。\n['sport', 'entertainment', 'tech', 'business', 'politics']\n\n回答はカテゴリのみ単語で返すこと。\n"}]}},"response":{"candidates":[{"avgLogprobs":2.0009465515613556e-06,"content":{"parts":[{"text":"\"business\""}],"role":"model"},"finishReason":"STOP"}],"createTime":"2025-03-19T09:36:26.693855Z","modelVersion":"gemini-2.0-flash-001@default","responseId":"GpDaZ9-sKoSVsbQPkc_vwQs","usageMetadata":{"candidatesTokenCount":3,"candidatesTokensDetails":[{"modality":"TEXT","tokenCount":3}],"promptTokenCount":523,"promptTokensDetails":[{"modality":"TEXT","tokenCount":523}],"totalTokenCount":526}}}
{"status":"","processed_time":"2025-03-19T09:36:26.584+00:00","request":{"contents":[{"parts":[{"text":"A next【省略】2010.\n"}],"role":"user"}],"generationConfig":{"responseMimeType":"application/json","responseSchema":{"enum":["sport","entertainment","tech","business","politics"],"type":"string"},"seed":0,"temperature":0},"labels":{"id":"n5"},"systemInstruction":{"parts":[{"text":"\nユーザーが与えるテキストを以下のカテゴリに分類せよ。\n['sport', 'entertainment', 'tech', 'business', 'politics']\n\n回答はカテゴリのみ単語で返すこと。\n"}]}},"response":{"candidates":[{"avgLogprobs":-0.13412895798683167,"content":{"parts":[{"text":"\"tech\""}],"role":"model"},"finishReason":"STOP"}],"createTime":"2025-03-19T09:36:26.698923Z","modelVersion":"gemini-2.0-flash-001@default","responseId":"GpDaZ6vUKoSVsbQPkc_vwQs","usageMetadata":{"candidatesTokenCount":3,"candidatesTokensDetails":[{"modality":"TEXT","tokenCount":3}],"promptTokenCount":471,"promptTokensDetails":[{"modality":"TEXT","tokenCount":471}],"totalTokenCount":474}}}
なお、ドキュメントには書かれていませんが、バッチ予測ジョブの詳細はコンソールからも確認できるようです。
Vertex AI > バッチ予測 にアクセスし、リージョンを適切に選択してジョブを確認してみてください。
分類の結果
参考までに、Gemini のバッチ予測の結果をデータセットの category カラムと比較してみました。
比較する際は、リクエストに含まれる labels.id を参照し、そのインデックスに対応する category カラムの値と比較しました。
結果は以下の通りで、すべてのデータに対して正しく分類されていました。
import json
import csv
categories = []
with open("bbc_news-fulltext.csv", "r", encoding="utf-8") as f:
reader = csv.reader(f)
next(reader)
for row in reader:
categories.append(row[1])
with open("predictions.jsonl", "r", encoding="utf-8") as f:
for line in f:
d = json.loads(line)
got = d['response']["candidates"][0]["content"]["parts"][0][
"text"].strip('"')
index = d["request"]["labels"]["id"].strip("n")
expected = categories[int(index)]
print(
f"Expected: {expected}, Got: {got}, Result: {'OK' if expected == got else 'NG'}"
)
# Expected: business, Got: business, Result: OK
# Expected: tech, Got: tech, Result: OK
# Expected: tech, Got: tech, Result: OK
# Expected: sport, Got: sport, Result: OK
# Expected: politics, Got: politics, Result: OK
# Expected: business, Got: business, Result: OK
# Expected: politics, Got: politics, Result: OK
# Expected: sport, Got: sport, Result: OK
# Expected: entertainment, Got: entertainment, Result: OK
# Expected: entertainment, Got: entertainment, Result: OK
まとめ
今回は、Gemini のバッチ予測機能を試してみました。バッチ予測を使うと、リクエスト容量を気にせずに、大量のデータに対して Gemini を適用することができます。試しに 1 万件のデータを処理してみたところ、処理時間は 8 分程度ととても速かったです。この機会に、ぜひバッチ予測を使ってみてはいかがでしょうか。
最後に
自社に専門人材がいない、リソースが足りない等の課題をお持ちの方に、エンジニア領域の支援サービス(Data Engineer Hub)をご提供しています。 お困りごとございましたら是非お気軽にご相談ください。
本件に関するお問い合わせは下記にて承ります。
株式会社DataCurrent
info@datacurrent.co.jp