2021.06.24 コラム
【API・データ検証奮闘記】#11.YouTube Data APIやってみた
本コラムでは、APIやデータに関連する言語などを無邪気に触ってみた備忘録として、ライトに記載していきます!
「ちょっと違くない」「他にいい方法あるのに」といったご意見もあるかと思いますが、何卒お手柔らかに!!
<プロフィール>
富松 良介
2017年、株式会社サイバー・コミュニケーションズ(CCI)入社。Oracle Bluekai・Treasure Data等のDMPや、AWS・GCP等のPublicCloud領域を担務。2019年6月よりデータの利活用を推進するコンサルティング会社「株式会社DataCurrent」に出向し、事業会社の基盤構築・運用や自社ソリューション開発を担当。
●YouTube Data APIやってみた

ボス
YouTubeの再生数やコメントの情報データを取得して欲しい。

モブ
!?
かしこまり!!
かしこまり!!
YouTube Data APIでデータ取得する手順から格納した結果までをご紹介致します。
●ステップ1. YouTubeデータ取得調査してみた

モブ1
管理画面からダウンロードする!?
モブ1
プログラムつくる!?
モブ2
ツール契約する!?

意識高いモブ
YouTube Data APIを使えば、VideoIDをもとに動画コメントや再生数を取得できるよ!

モブ
YouTube Data APIで取得することにしよう!!
ボス
それでやってくれ。
●ステップ2. YouTube Data APIでデータ取得してみた
早速APIをたたいてみる。
from apiclient.discovery import build
import math
import time
YOUTUBE_API_KEY = 'YOUR_API_KEY '
class YouTube(object):
def __init__(self, developerKey):
super(YouTube, self).__init__()
self.instance = build('youtube', 'v3', developerKey= developerKey)
def fetch_commentThreads(self, videoId, order, nextPageToken=None):
res = self.instance.commentThreads().list(
part='snippet',
maxResults=100,
videoId=videoId,
order=order,
textFormat='plainText',
pageToken=nextPageToken
).execute()
return res
def fetch_search(self, channelId, nextPageToken=None):
res = self.instance.search().list(
part='snippet',
maxResults=50,
regionCode='JP',
order='viewCount', #視聴回数が多い順に取得
type='video',
channelId=channelId,
pageToken=nextPageToken
).execute()
return res
def fetch_play(self, videoId, nextPageToken=None):
print(nextPageToken)
res = self.instance.videos().list(
part = ['statistics'],
maxResults = 50,
regionCode = 'JP',
pageToken=nextPageToken,
id=videoId
).execute()
return res
def fetch_all_commentThreads(self, videoId, order):
res = self.fetch_commentThreads(videoId, order, nextPageToken=None)
nextPageToken = res.get('nextPageToken')
print(nextPageToken)
while ('nextPageToken' in res):
time.sleep(0.5)
nextPage = self.fetch_commentThreads(videoId, order, nextPageToken=nextPageToken)
res['items'] = res['items'] + nextPage['items']
if 'nextPageToken' not in nextPage:
res.pop('nextPageToken', None)
else:
nextPageToken = nextPage['nextPageToken']
return res
def fetch_all_search(self, channelId):
res = self.fetch_search(channelId, nextPageToken=None)
nextPageToken = res.get('nextPageToken')
print(nextPageToken)
while ('nextPageToken' in res):
time.sleep(0.5)
nextPage =self. fetch_search(channelId, pageToken=nextPageToken)
res['items'] = res['items'] + nextPage['items']
if 'nextPageToken' not in nextPage:
res.pop('nextPageToken', None)
else:
nextPageToken = nextPage['nextPageToken']
return res
def fetch_all_play(self, videoId):
videoIds = []
if isinstance(videoId, str):
res = self.fetch_play(videoId, nextPageToken=None)
elif isinstance(videoId, list):
requestNum = math.ceil(len(videoId)/50)
for i in range(requestNum):
elementStart, elementEnd = i*50, (i+1)*50
videoIds.append(videoId[elementStart:elementEnd])
for j,video in enumerate(videoIds):
if j==0:
res = self.fetch_play(video, nextPageToken=None)
else:
nextVideos = self.fetch_play(video, nextPageToken=None)
res['items'] = res['items'] + nextVideos['items']
time.sleep(0.5)
else:
raise ValueError("videoIdを[str]またはstrの形式で指定します")
return res
youtube = YouTube(YOUTUBE_API_KEY)
#再生数取得
res = youtube.fetch_all_play(
videoId=videoId
)
#コメント取得
res = youtube.fetch_all_commentThreads(
videoId=videoId,
order='time'#relevance,time
できた!!!
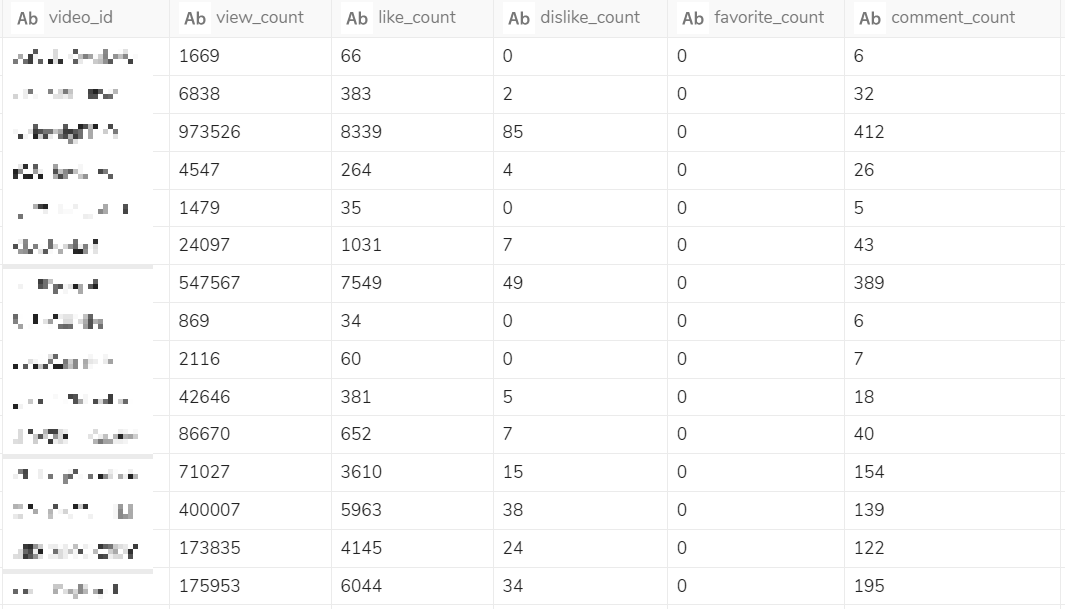
●ステップ3. 取得結果
動画ごとの再生数やいいね数
動画へのコメント

意識高いモブ
ちなみに、APIコールの上限があるので大量にデータを取得する場合、Google社に上限申請の申し入れとレビューが必要だよ!
●最後に
弊社では、ツール間のデータ連携や設定方法はもちろん、その他データの取り扱いに関する課題に対してトータルで支援しております。
お困りごとございましたら、お気軽にお問い合わせください。
本データに関するお問い合わせは下記にて承ります。
株式会社DataCurrent
info@datacurrent.co.jp