2021.04.26 コラム
【API・データ検証奮闘記】#6.WorkflowでHTMLデータを取得してみた
本コラムでは、APIやデータに関連する言語などを無邪気に触ってみた備忘録として、ライトに記載していきます!
「ちょっと違くない」「他にいい方法あるのに」といったご意見もあるかと思いますが、何卒お手柔らかに!!
<プロフィール>
富松 良介
2017年、株式会社サイバー・コミュニケーションズ(CCI)入社。Oracle Bluekai・Treasure Data等のDMPや、AWS・GCP等のPublicCloud領域を担務。2019年6月よりデータの利活用を推進するコンサルティング会社「株式会社DataCurrent」に出向し、事業会社の基盤構築・運用や自社ソリューション開発を担当。
●HTMLデータ取得をしてみた

ボス
Webサイトのデータをとって欲しい。

モブ
かしこまり!!
TreasureData workflowを活用したHTMLデータ取得の手順から取得した結果までをご紹介致します。
●ステップ1. どうやって取得できるか調査してみた

モブ1
有料のツール契約する!!
モブ2
HTMLソースから気合と根性で手動コピペ!!
モブ3
Python!!

意識高いモブ
Workflowなら取得から格納までワンストップだぜ!!

モブ
Treasure Data Workflowで取得することにしよう!!
ボス
それでやってくれ。
●ステップ2. データ取得してみた
早速Workflowでデータを取得してみる。
弊社コーポレートサイトの、最新の新着情報を取得してみます!
※データ取得する際は、サイト利用規約等を確認し実施してください。
timezone: Asia/Tokyo
_export:
td:
database: your_database
table: your_table
base_endpoint: https://www.datacurrent.co.jp/
date: ${moment(session_time).format("YYYY-MM-DD HH:mm:ss")}
+get_data:
for_each>:
directory: ['news-latest']
_do:
+request:
http>: ${base_endpoint}${directory}/
method: GET
store_content: true
+write_to_table:
td>:
query: |
SELECT
'${directory}' AS directory,
regexp_extract(
'${(http.last_content).replaceAll(regex, "").match("<tr>.+?</tr>")}',
'[\d]{4}\.[\d]{2}\.[\d]{2}'
) AS relese_date,
regexp_replace(
'${(http.last_content).replaceAll(regex, "").match("<tr>.+?</tr>")}',
'^.+?<span class=\\"el_news\\">|</span>.+?$',
''
) AS content_category,
regexp_replace(
'${(http.last_content).replaceAll(regex, "").match("<tr>.+?</tr>")}',
'^.+?alt=\\\"|\\.*?$|</a></td></tr>\"\]$',
''
) AS content_title,
'${get_date}' AS get_date
insert_into: ${td.database}.${td.table}
engine: presto
できた!!!
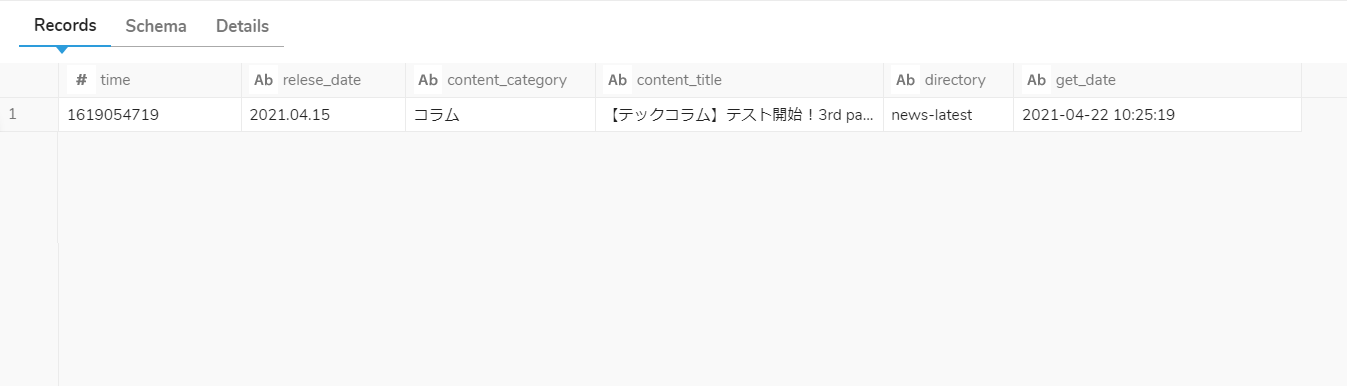
●ステップ3. 取得結果
●最後に
弊社では、定点的なリサーチやトレンドの分析をおこなっています。性別や年代等の属性を検索トレンドのダッシュボード提供等様々なパッケージをご用意しておりますので、お気軽にお問い合わせください。
本データに関するお問い合わせは下記にて承ります。
株式会社DataCurrent
info@datacurrent.co.jp