2020.09.01 コラム
【API・データ検証奮闘記】#1.Twitter APIやってみた
本コラムでは、APIやデータに関連する言語などを無邪気に触ってみた備忘録として、ライトに記載していきます!(連載記事はこちら)
「ちょっと違くない」「他にいい方法あるのに」といったご意見もあるかと思いますが、何卒お手柔らかに!!
<プロフィール>
富松 良介
2017年、株式会社サイバー・コミュニケーションズ(CCI)入社。Oracle Bluekai・Treasure Data等のDMPや、AWS・GCP等のPublicCloud領域を担務。2019年6月よりデータの利活用を推進するコンサルティング会社「株式会社DataCurrent」に出向し、事業会社の基盤構築・運用や自社ソリューション開発を担当。
●Twitter APIやってみた
今更ながらTwitter APIのデータを使ってトレンドの分析に活用することができないか考えました。
インターネット上にある先人たちの記事も参考に、特定キーワードに関連するツイートを取得・集計し、 データ取得に至るまでの過程から取得したデータをどう活用したかについてご紹介致します。
| API名 | Twitter Standard API(Search Tweets) ※詳細 https://developer.twitter.com/en/docs/tweets/search/api-reference/get-search-tweets |
| 費用 | 無料 |
| 制限 | 180 APIコール / 15分 最大 100 件 / 1 APIコール ※詳細 https://developer.twitter.com/ja/docs/basics/rate-limiting |
●ステップ1. Twitter Standard APIの利用申請
Twitter DevelopersでAPIの利用申請を行い、API KEYを取得する必要があります。
申請方法は「Twitter API 申請方法」とかでググっていただくと幸せになれます。
●ステップ2. まずはTwitter APIを叩いてみた
早速API KEYを使ってPythonでデータ取得してみる。
import urllib
from requests_oauthlib import OAuth1
import requests
from datetime import datetime, timedelta
import pandas as pd
import pytz
timezone = pytz.timezone('Asia/Tokyo')
ts = datetime.now(tz=timezone)
until_ts = ts + timedelta(weeks=-1)
until = '{0:%Y-%m-%d}'.format(until_ts)
def main():
# APIKEY
CONSUMER_KEY = 'XXXXXXXXXXXXXXXXXXXXXXXXX'
CONSUMER_SECRET = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
ACCESS_TOKEN = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
ACCESS_TOKEN_SECRET = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
# paramater
word = "ハンドソープ"
count = 100
search_range = 1#80
tweets = search_tweets(CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET, word, count, search_range)
result_df = pd.DataFrame(
tweets,
index=None,
columns=['TweetID',
'PostedTime',
'UserName',
'UserID',
'UserScreenName',
'UserFavourites',
'UserFollowers',
'UserFriends',
'PostRetweet',
'PostFavorite',
'PostMessage'])
def search_tweets(CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET, word, count, search_range):
word = urllib.parse.quote_plus(word)
url = "https://api.twitter.com/1.1/search/tweets.json?lang=ja&q="+word+"&count="+str(count)
auth = OAuth1(CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
response = requests.get(url, auth=auth)
data = response.json()['statuses']
cnt = 0
tweets = []
while True:
if len(data) == 0:
break
cnt += 1
if cnt > search_range:
break
for tweet in data:
tweets.append([
tweet['id_str'], # ツイートID
'{0:%Y-%m-%d %H:%M:%S}'.format(datetime.strptime(tweet['created_at'], "%a %b %d %H:%M:%S %z %Y") + timedelta(hours=9)), # 投稿日
tweet['user']['name'], # ユーザー名
tweet['user']['id_str'], # ユーザーID
tweet['user']['screen_name'], # ユーザー表示名
tweet['user']['favourites_count'], # ユーザーお気に入り数
tweet['user']['followers_count'], # フォロワー数
tweet['user']['friends_count'], # フレンド数
tweet['retweet_count'], # リツイート数
tweet['favorite_count'], # 投稿お気に入り数
tweet['text'] # 投稿文
])
maxid = int(tweet["id"]) - 1
url = "https://api.twitter.com/1.1/search/tweets.json?lang=ja&q="+word+"&count="+str(count)+"&max_id="+str(maxid)
response = requests.get(url, auth=auth)
try:
data = response.json()['statuses']
except KeyError:
break
return tweets
if __name__ == '__main__':
main()
取得結果
※後述の背景があり、取得データにモザイク処理を施しています。

●ステップ3. 詳しい人に突撃してみた
今回は色々詳しい4人の方に突撃して、課題やTipsがないか聞いてみました!



シュババババ …!!!!Twitter IDは個人情報に該当するよ!!!!

Twitterユーザー名(UserName)やユーザー表示名(UserScreenName)はフルネームを使っていたり、
プロフィール文と組み合わせる事で特定の個人を識別できる可能性があるので、
個人情報として扱ってください。

法律上どちらも”個人情報”と明記されておりませんが、
”個人情報でない”とも明記されておりません。
いわゆるグレーな位置づけです。
実際に個人を特定できるものもあれば、できないものもあります。
しかし、1つ1つ仕分けることは現実的に難しいためまとめて個人情報として扱う方針です。
個人情報保護委員会の「個人情報保護法ガイドライン(通則編)」には、
個人情報の”事例”としてメールアドレス、SNSアカウントが記載されております。
https://www.ppc.go.jp/files/pdf/guidelines01.pdf

●ステップ4. 突撃した結果
・ツール化してもらった
当初取得していたSearchAPIを使って、定期的に任意のキーワードを指定して取得する仕様で設計。
・取得したデータは個人情報として取り扱うことにした
SNSのID等は個人情報に該当すると判断されたため、ISO27001の規則にのっとり個人情報として取扱う事になりました。
●ステップ5. アウトプットしてみた
TwitterとYahoo! DS.INSIGHTでそれぞれ「ハンドソープ」に関連する日別データを取得し、7/10の取得開始日を基準時点にし日毎の値を比較時点として変化率を算出しました。
・計算式
(比較時点 - 基準時点)÷ 基準時点 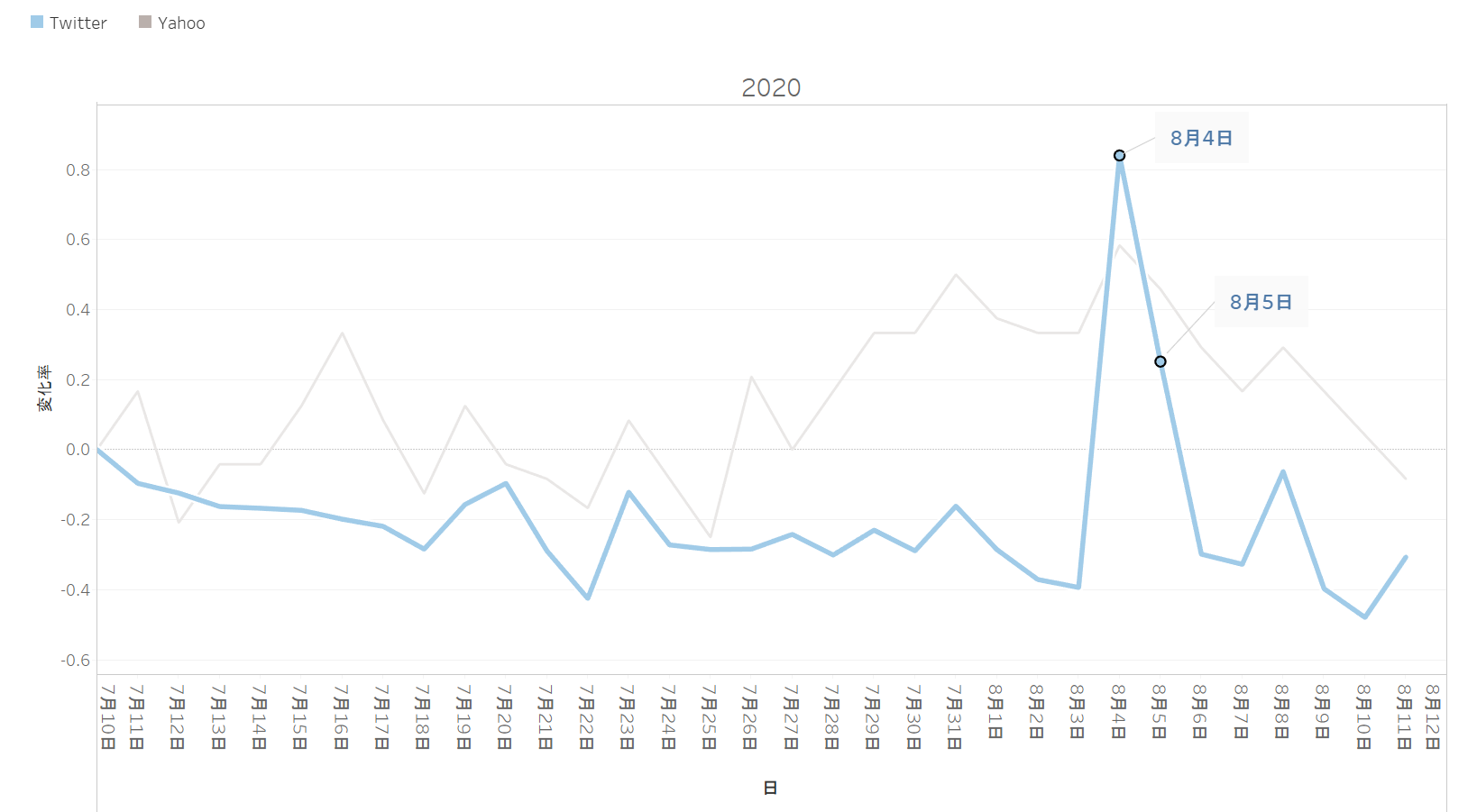
結果をみてみると、どちらのデータソースも8月4日~8月5日が最大の変化率となっています。
また、Yahoo! DS.INSIGHTの検索データと比べてTwitterのユーザーツイートの方がより顕著に変化を示しています。
※8月4日と8月5日のニュースを漁ってみたら、8月4日に大阪府が「ポピドンヨード」に関連する会見をしていました。
一時期の「ハンドソープのまとめ買い」が共起された人が多くいたのか、トレンドデータからこのような形で読み取ることができました。
●最後に
弊社では、定点的なリサーチやトレンドの分析をおこなっています。性別や年代等の属性を検索トレンドのダッシュボード提供等様々なパッケージをご用意しておりますので、お気軽にお問い合わせください。
本データに関するお問い合わせは下記にて承ります。
株式会社DataCurrent
info@datacurrent.co.jp